
Watson: ein geschickt gewählter Name mit starkem Marketing ausgerollt, mitunter gescholten und oftmals schlecht erklärt. Die frühen Marketingversprechen dürfen als »ambitioniert« bezeichnet werden. Ein kleiner Blick zurück: IBM baute einen Supercomputer auf der Basis dutzender Power-Systeme jeweils mit mehreren Terabyte RAM (!). Benannt wurde das System nach dem IBM-Gründer Thomas Watson. Dieses System wurde mit Daten aus Wikipedia, Wörterbüchern und vielen anderen Quellen gefüttert. Eine elastische Suche, Sprachverarbeitungstechnologien und Expertensysteme versetzten den Rechnerverbund in die Lage, an der Quiz-Show Jeopardy teilzunehmen – und zu gewinnen! Das erste Mal im Februar 2011.
Eine Maschine besiegt die schlauesten quizzenden US-Amerikaner bei der Formulierung von Fragen wie »Was ist Stockholm« auf die Aussage »Dublin, Stockholm, Paris« in der Kategorie »Nördlichste Hauptstädte«. Geografische Fragen sind natürlich für einen Computer ein Kinderspiel, aber auch bei historischen Angaben glänzte Watson und konnte schneller als die menschlichen Kandidaten etwa die Frage nach der Nachfolge von Christian Dior im Modehaus Dior beantworten, auch wenn es bei ihm da ein bisschen mit der Sprache haperte (mit seiner sehr amerikamischen Version von »Yves Saint Laurent«). Das Ergebnis war großartig und faszinierend. Der Computer gewann gegen die Menschen. Gut, das Preisgeld reichte nicht ganz, um die Entwicklungskosten abzudecken.
Mit Stolz ging das Unternehmen daran, viele andere Herausforderungen in die Hände von Watson zu legen. Dabei war Watson längst nicht mehr der Supercomputer-Verbund aus Jeopardy. Vor allem wurde der Begriff Watson immer schwammiger: Keineswegs war mit Watson immer der Supercomputer von Jeopardy gemeint, manchmal war es eben nur ein Software-Tool, manchmal die Cloud-Landschaft von IBM, mal eine IoT-Plattform, mal KI-Technologie. Selbst in IBMs Geschichte kam es bislang nicht vor, dass die nahezu gesamte Linie an Produkten und Services unter einem Begriff vermarktet wurde. Das führte eben auch zu Enttäuschungen.
Inzwischen hat Watson, wenn man es so sagen möchte, die Pubertät fast schon hinter sich gelassen. »Er« ist nicht mehr der alles besserwissende Kerl, der die Welt erobern oder zumindest umkrempeln will. Watson wird nun als Plattform beschrieben, mit der Anwender ihre IT-Aufgaben umsetzen können.
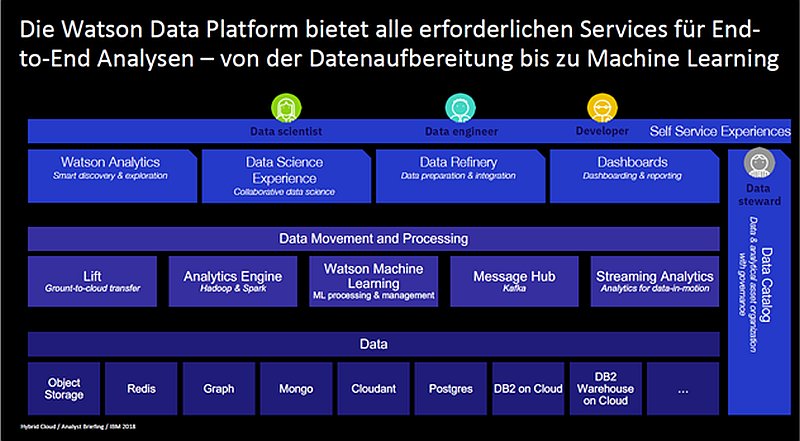
Abbildung: IBMs »Watson« ist nun eine Plattform für fortgeschrittene IT-Anwendungen. Quelle: IBM.
Viele Komponenten von Watson sind Open Source, beispielsweise für die Datenverwaltung und die Programmierung, teils mit erheblichen Veredelungen. »Notebooks« genannte Anleitungen ermöglichen eine moderne Applikationsentwicklung. Die Notebooks erläutern dem Entwickler schrittweise, welche Funktionen aus den umfangreichen Programmbibliotheken für die Datensammlung, die Datenaufbereitung, die Analyse und die Visualisierung benötigt werden. Die Entwicklungsumgebung unterstützt neben dem klassischen Schreiben von Code auch die Programmierung mit Wizards oder das visuelle Modellieren von Analyseverfahren. Diese Form der Entwicklerunterstützung sollte geeignet sein, anspruchsvolle Aufgaben auch dann zu entwickeln, wenn nicht alle Personen im Team ausgebuffte Python-Coder und -Coderinnen sind.
Noch ein Stück weiter geht das Paket »Watson Business Solutions«. Damit sollen aus vorgefertigten Funktionen individuell entwickelte Routinen und Dokumente, etwa virtuelle Help-Desk-Agenten entstehen.
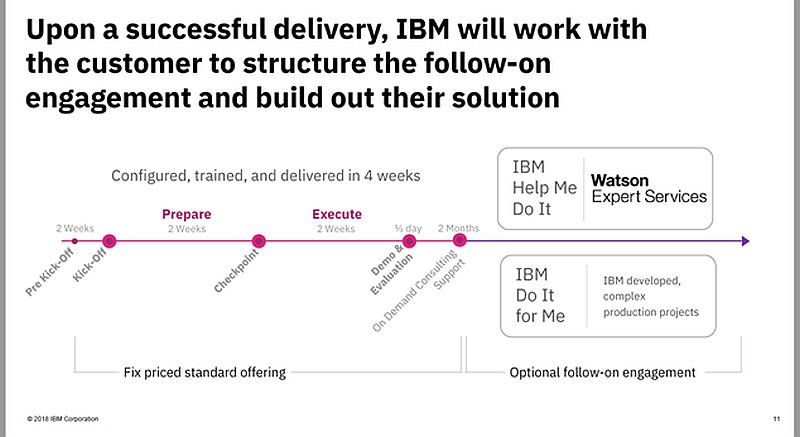
Abbildung: Watson Business Solutions bündelt zur schnellen Applikationsentwicklung vorgefertigte Funktionen für typische Unternehmensprozesse mit weiteren Watson-Technologien. Quelle: IBM.
Dahinter stehen wiederum Cloud Services, die als Software as a Service genutzt werden können. Watson hat sich also tatsächlich entwickelt: vom Tausendsassa zu einem Kollegen, der weiß, wohin man Daten packt und wie man Anwendungen entwickelt.
Holm Landrock, ISG, www.isg-one.com
Die Watson-Technologie ins richtige Licht rücken: Watson, wir haben (k)ein Problem
Große Konzerne, Start-ups und Kooperationen investieren gerne in künstliche Intelligenz (KI): 2016 flossen zwischen 26 und 39 Milliarden US-Dollar in die Forschung und Entwicklung kognitiver Systeme und Roboter, so eine Studie. In der jüngeren medialen Berichterstattung zur »KI« von IBM ist Watson aber ein wenig in Misskredit geraten. Einige großen Projekte etwa mit Versicherungskonzernen erbrachten bisher nicht die gewünschten Ergebnisse. Ein oft geäußerter Vorwurf dabei lautet, dass durch die offensive Medienkampagne von IBM zu Watson Erwartungen geweckt wurden, die die Technologie nicht beziehungsweise noch nicht erfüllen kann.
»Dieser Vorwurf zeigt jedoch auch ein großes Missverständnis in der öffentlichen wie geschäftlichen Wahrnehmung, in der Watson immer wieder als die den Menschen verstehende ›Maschine‹ personifiziert wird«, bemerkt Ursula Flade-Ruf, Geschäftsführerin der Management Informations Partner GmbH. Doch was ist denn Watson eigentlich genau?
»Diese Reduktion auf Watson als einzelne Maschine hat in der Vergangenheit sicher für die ein oder andere Verwirrung gesorgt«, so Markus Ruf, Geschäftsführer und Big-Data-Experte bei der mip GmbH. »Er ist aber weder ein einzelner Superrechner, noch eine irgendwie geartete individuelle KI. Vielmehr ist Watson eine Plattform verschiedenster Services und Verfahren, die auf derselben Technologie basieren. Es handelt sich bei Watson nicht um ein Produkt, sondern um viele Einzelprodukte. Auch sind diese meistens auf mehreren Rechnern installiert – von einer ›Maschine‹ oder einem ›Watson‹ kann also keine Rede sein.«
KIs im B2C und B2B – Vergleiche hinken
Zudem wird Watson gerne seinen KI-Brüdern und -Schwestern aus dem B2C-Bereich gegenübergestellt. »Ungerechterweise«, wie Flade-Ruf meint, »denn hier werden Äpfel mit Birnen verglichen. Die mit Watson verbundenen Services und Entwickler-Tools von IBM sind ausschließlich auf den B2B-Sektor ausgerichtet.« Alexa, Siri, Cortana, Google Home und Co. haben es hingegen mit den Endkunden im B2C erheblich einfacher, rasche Erfolge vorzuweisen, da sie jeden Tag von Millionen Menschen genutzt, mit Informationen gefüttert und dadurch stetig trainiert werden.
Dass diese Geräte schnell eine große Menge an Informationen zu Personen und ihren Vorlieben ansammeln und dann auch anwenden, ist leicht nachvollziehbar. Allerdings geschieht dies durch ein ständiges Mithören, was eigentlich jeden Nutzer aufhorchen und vorsichtiger werden lassen sollte. Wem die Daten am Ende gehören und wo sie genau gespeichert sind (was wichtig für die Datenschutzrichtlinien ist), ist meist nicht eindeutig geklärt oder steht gut versteckt im Kleingedruckten.
Daten bleiben Eigentum der Watson-Nutzer
»Solch ein Vorgehen unterscheidet sich erheblich vom projektbezogenen, individuellen Daten-Training mit Watson«, meint Flade-Ruf. »Hier hat IBM zudem eine Art Code of Conduct für Cloud Services in Verbindung mit KI-Daten verfasst, sodass die innerhalb eines Projekts gewonnenen Informationen immer Eigentum der jeweiligen Service-Nutzer bleiben – und bisher hält sich IBM auch daran.« Damit lässt sich auch der Vorwurf einiger Unternehmen entkräften, dass man ja bei Watson nicht genau wisse, wem schließlich sowohl die eingespielten als auch die neu gewonnenen Daten gehören würden. Unterm Strich lassen sich die KIs durch die völlig verschiedenen Zielrichtungen der Hersteller und Einsatzgebiete nur schwer bis überhaupt nicht miteinander vergleichen.
Watson-Projekte benötigen einen längeren Atem – zeitlich und finanziell
Künstliche Intelligenz ist kein neues Phänomen. Schon seit Jahrzehnten taucht der Begriff in Verbindung mit Regressionsanalysen, Clustering oder Multivariable-Verfahren auf. Dem autonomen Lernen wird dabei eine besonders große gesellschaftliche sowie wirtschaftliche Bedeutung zugemessen, was unter anderem das nahezu exponentielle Wachstum von Fundraising-Projekten rund um Start-ups im Bereich Deep oder Machine Learning erklärt.
Nach den jüngsten Kritiken zu urteilen haben aber scheinbar viele Unternehmen den Aufwand, der mit einem Watson-Projekt auf ein Unternehmen zukommt, unterschätzt. »So hat ein Beispiel eines Kunden aus der Bekleidungsbranche gezeigt, wie viel Arbeit etwa ein Training von Watsons Visual Recognition kosten kann«, wirft Ruf ein. »Für die visuelle Unterscheidung von Kleidungsstücken wurden rund 30.000 Bilder benötigt, bis der Service autonom funktionierte.« Auch in der Medizin oder bei Versicherungsfällen muss eine riesige Menge an Daten herangezogen werden, um eine verlässliche statistische Auswertung zu ermöglichen. »Die Intelligenz der Programme und Services wird natürlich stetig weiterentwickelt«, ergänzt Markus Ruf. »Die Wissensdatenbanken, die sich dahinter verbergen, müssen allerdings den Watson-Systemen in den einzelnen Projekten immer wieder neu beigebracht werden.«
Kooperationen entscheidend für Weiterentwicklung von KI
Um solche Mengen an Daten bereitstellen und die zur Verfügung stehenden KI-Services voll ausnutzen zu können, seien Kooperationen unerlässlich, so Flade-Ruf. »Viele Unternehmen sind auf bestimmte Bereiche wie etwa visuelle Wahrnehmung und Verarbeitung, Robotik, Sprachverarbeitung und -analyse oder Datenauswertung spezialisiert und müssen deshalb auch in komplexe Watson-Projekte miteinbezogen werden.« Unter anderem arbeiten IBM, Apple, Amazon, die Google-Tochter Deep Mind, Facebook und Microsoft an gemeinsamen Projekten rund um das Thema künstliche Intelligenz. »IBM hat zudem die Plattform PowerAI installiert, auf der von verschiedenen Herstellern Frameworks zu Deep Learning und unterstützende Datenbanken angeboten werden«, erklärt Flade-Ruf. »Das Unternehmen präsentiert sich in diesem Zusammenhang auch sehr offen: Es gibt einige Open-Source-Projekte oder freie Services aus der Bluemix Cloud.« Am Ende möchte IBM möglichst viele Experten unter seinem technologischen Dach vereinen, um die Watson-Funktionalitäten künftig noch erheblich zu erweitern.
Konkrete erfolgreiche Anwendungsbeispiele selten
Eine Schwierigkeit im Zusammenhang mit Watson-Projekten ist das Fehlen von allgemeingültigen weltweiten Anwendungsfällen, wie sie im B2C-Bereich mit Alexa, Siri oder Cortana vorhanden sind. »Watson-Projekte sind dagegen äußerst industrie- und unternehmensspezifisch«, erklärt Flade-Ruf. »Vieles passiert hier hinter verschlossenen Türen, da sich niemand zu früh von Mitkonkurrenten in die KI-Karten schauen lassen möchte.« Ein großer Teil stammt dabei aus dem Bereich Internet of Things (IoT) im industriellen Sektor. Big Data in Form von Sensor- und Maschinendaten soll dort im Predictive-Maintenance-Umfeld und zur Qualitätssicherung eingesetzt werden. IBM kooperiert beispielsweise mit Unternehmen wie Schaeffler, Bosch, BMW, Citroen, Renault etc.
Ein anderer Bereich, in dem ein großes Potenzial gesehen wird, ist die Unterstützung von Call-Centern und -Services etwa im Öffentlichen Dienst oder Versicherungs- und Banking-Umfeld, aber auch im technischen Support. Hier sollen KI-gestützte Systeme automatisch Kunden identifizieren und Empfehlungen zum Umgang mit diesen an die Sachbearbeiter vorschlagen.
Die Nachfrage nach künstlicher Intelligenz steigt auch in der Ausbildung. »So haben Experten von IBM und der mip GmbH einen halbtägigen Workshop zum Thema ›Künstliche Intelligenz – Watson Services für Chat-Bots nutzen‹ an der Technische Hochschule Nürnberg abgehalten«, bemerkt Ruf. Die Studenten konnten im Verlauf der Veranstaltung die verschiedenen Cloud-Services von Watson ausprobieren und beispielsweise die Spracherkennung des Bots trainieren.
KI-gestützte Chatbots voll im Trend
Einen Schritt weiter gehen intelligente Chatbots, die eigenständig komplette Chat-Sessions mit Kunden oder Mitarbeitern bewältigen können, um etwa FAQs zu beantworten oder Bestellungen abzuwickeln. »Auf dem Watson Summit wurde ein Chatbot vorgestellt, der Siemens für das eigene Personal basierend auf den IBM Conversation Services und anderen Watson-Tools entwickelt wurde«, so Flade-Ruf. Mitarbeiter können mit diesem interagieren und erhalten automatisiert Antworten auf ihre Fragen.
Auch im juristischen Umfeld könnten eine Vielzahl an einfacheren Rechtsfällen über einen Watson-Service abgebildet werden. DoNotPay ist ein Beispiel für einen intelligenten Chatbot, der Nutzer in kleinen Rechtsfragen wie etwa Falschparken unterstützt.
Ein weiteres Feld umfasst das Thema Enterprise Search, in dem Watson-basierte Tools wie das Natural Language Processing zur Verarbeitung menschlicher Sprache und das Watson Knowledge Studio, welches ein branchenspezifisches Training ohne Programmierungskenntnisse ermöglicht, eingesetzt werden. »Mit Enterprise-Search-Systemen lassen sich schnell große Mengen an Informationen durchsuchen und personenbezogen aufbereiten«, erklärt Ruf. Die Lösung lernt dabei, welche Informationen für den jeweiligen Nutzer besonders relevant sind und zeigt diese dann übersichtlich in einem Dashboard an.
Ist Watson mittelstandstauglich?
Neben all dem Interesse an der künstlichen Intelligenz offenbart die McKinsey-Studie aber auch, dass sich kleine und mittelgroße Unternehmen in diesem Bereich noch schwer mit der Umsetzung von Projekten tun: So setzen gerade einmal neun Prozent bereits maschinelles Lernen im größeren Maßstab ein. Nur zwölf Prozent gaben an, dass sie das Experimentierstadium bereits verlassen hätten.
»Unser Rat ist, dass Unternehmen mit der Umsetzung von Watson-Projekten erst einmal klein anfangen sollten«, bemerkt Flade-Ruf. »Watson ist kein fertiges Produkt und vor dem Training sozusagen noch ›dumm‹. Deshalb müssen Ziele und Trennschärfen im Vorfeld klar formuliert werden.«
Umso eindeutiger sich Themen definieren und Grenzen ziehen lassen, desto einfacher und schneller lässt sich auch zum Beispiel ein Chatbot aus den verschiedenen Watson-Komponenten zusammenstellen und mit einer spezifischen Wissensdatenbank trainieren.
»Zudem ist ein großes Team erforderlich, dass sich aus unterschiedlichen Qualitäten zusammensetzt, die die von üblichen IT-Projekten übersteigen«, so Flade-Ruf: »Man benötigt unter anderem Business-User sowie -Analysten, KI-Experten, Programmierer, Prozess-Spezialisten für die Einbindung der KI in die Systemlandschaft.«
Ein weiterer Punkt, der bei Watson-Projekten bedacht werden muss, ist die Ausrichtung aller Watson-Services auf die Cloud. »Das ist auch sinnvoll, da es zum Beispiel gerade im Bereich Sensorik meist um Maschinendaten aus Anlagen auf der ganzen Welt geht«, bestätigt Ruf. »Hier müssen sich die Kunden also in ihrer Unternehmensstrategie entscheiden, welchen Weg sie gehen wollen.«
Viele KI-Experimente, wenig Ertrag
Im Watson-Umfeld tut sich viel, doch fehlen vielerorts noch die Erträge. Flade-Ruf: »Leider erkennen wir gerade den Trend, dass Unternehmen Projekte in Eigenregie durchführen – und dabei oft scheitern, ohne die entsprechenden Schlüsse daraus zu ziehen.« Dabei bieten der Markt oder auch Watson selbst viele Open-Source-Möglichkeiten an, um Wettbewerbsvorteile zu generieren oder neue Geschäftsmodelle aufzubauen. Experimentieren ist dadurch also nahezu ohne große eigene finanzielle Aufwände möglich.
»Das Scheitern solcher Ansätze, wie etwa im Start-up-Umfeld, ist ein immanenter Bestandteil solcher Experimente«, bemerkt Flade-Ruf. »Jedoch hat sich in Deutschland bisher keine ›Fast-Fail-Kultur‹, also der schnelle Übergang von einem Fehlschlag zu einem neuen optimierten Versuch, entwickeln können.«
Dieser Trend fordert IT-Dienstleister heraus, da es immer schwieriger wird, die eigene Expertise in solche Projekte einzubringen. Viele Firmen befürchten scheinbar, dass KI-Know-how über externe Berater zur Konkurrenz wandern könnte. Ruf: »Auf der anderen Seite können Unternehmen von den Erfahrungen von Spezialisten wie uns spürbar profitieren, um beispielsweise Projekte schneller erfolgreich abschließen zu können.«
Die mip Management Informationspartner GmbH ist seit fast 30 Jahren ein zuverlässiger Partner und Ideengeber für mittelständische sowie große Unternehmen, die ihre Unternehmensdaten intelligent verknüpfen und profitabel einsetzen wollen. Mit dem Hauptsitz in München und einer Niederlassung in Stuttgart agiert das Unternehmen vom Süden Deutschlands aus im gesamten deutschsprachigen Raum. Die Schwerpunkte liegen seit der Firmengründung 1988 in den Bereichen Data Warehouse und Business Intelligence. Heute berät die mip GmbH mittelständische sowie große Unternehmen und entwickelt für diese nutzenorientierten Datenanalyse-Lösungen als Basis für die digitale Transformation. Dabei stehen Data-Warehouse-, Business- und Predictive-Analysis- sowie Enterprise-Search-Lösungen im Vordergrund. Strategische Partnerschaften mit großen Herstellern und spezialisierten Häusern sorgen für den technologischen Unterbau. Weitere Informationen finden auf https://mip.de/mip-gmbh/.
ERP-Trends 2018: Geschäftssoftware fit für künftige Herausforderungen machen
Anbietervergleich: Social Enterprise Networking Suites verbessern die Zusammenarbeit im Unternehmen
Was sind Chatbots, was können sie, und wann sind sie sinnvoll?