
Das Verständnis und das Wissen um die eigenen Daten ist die Grundlage jeglicher IT-Sicherheitsstrategie. DLP-Lösungen sollen Unternehmen vor unabsichtlichen Fehlern im Umgang mit vertraulichen Daten bewahren.
Data Leakage Prevention (DLP) ist eines der am meisten diskutierten, aber am wenigsten verstandenen Themen innerhalb der IT-Datensicherheit. Google listet mindestens 10 Firmen und deren Lösungsbeschreibungen bei Eingabe von DLP auf. Nach der Lektüre dieser Lösungsbeschreibungen ist die Verwirrung jedoch noch größer, was genau unter dem Begriff DLP zu verstehen ist und welcher Mehrwert sich durch die jeweilige Lösung ergeben soll.
Für DLP gibt es keine eindeutige Definition am Markt. IT-Security-Hersteller mit Port-Kontrollmechanismen von Endgeräten nutzen den Begriff genauso wie Anbieter von Dokumenten- und E-Mail-Verschlüsselung. Das SANS Institut hat im Rahmen von Analysen eine inzwischen allgemein akzeptierte Beschreibung von DLP geliefert: »DLP-Lösungen sind Lösungen, die IT-Daten als solche identifizieren, deren Nutzung überwachen und protokollieren sowie deren Bewegungen in und aus dem Unternehmen anhand zentraler Richtlinien kontrollieren, ggf. den Transfer unterbinden und dies über eine genaue Inhaltsanalyse der Daten erreichen.« [1]
Es gibt in der Tat sehr unterschiedliche technologische Ansätze, sich als Hersteller dieser Thematik zu nähern. Für potenzielle Nutzer hingegen gibt es genau einen Leitsatz, weshalb man sich mit DLP beschäftigen sollte: »Das Verständnis und das Wissen um die eigenen Daten ist die Grundlage einer jeglichen IT-Sicherheitsstrategie und der Wahrung von Vertraulichkeit.« [2]
Grundsätzlich ist zu sagen, dass sich die eigene IT-Sicherheitsstrategie wesentlich leichter gestalten und effektiver umsetzen lässt, wenn bekannt ist, welche Daten als vertraulich und damit als schützenswert einzustufen sind. Investitionen in die IT-Security können dann primär auf den Schutz dieser Daten ausgerichtet werden.
DLP-Lösungen sind also keine Analyse-Tools für möglichen, ausführbaren Schadcode und Verwundbarkeiten in Dateien und sie verhindern nicht dessen Verbreitung, sondern sie dienen primär der Absicherung von Geschäftsprozessen. Genauer gesagt schützen DLP-Lösungen vor unabsichtlichen Fehlern im Umgang mit vertraulichen Daten. Es ist auch wichtig, zwischen Lösungen, die nur Teilaspekte von DLP abdecken und meistens von Anbietern klassischer IT-Security stammen, und einer Gesamtlösung, die eine komplette Datenklassifizierung umfasst, zu unterscheiden. Teillösungen werden hauptsächlich von Security-Administratoren verwaltet, wohingegen komplette DLP-Lösungen eher im Verantwortungsbereich der juristischen Fachabteilung liegen. Die Einhaltung zentraler Vorgaben für den Umgang mit vertraulichen Daten sollte im Führungsbereich einer Firma verantwortet sein und nicht bei den IT-Security-Administratoren.
Die Aufgabe von DLP-Lösungen ist zweigeteilt. Einerseits sollen sensible Daten vor Verlust geschützt werden. Andererseits besteht der Wunsch, die Datenbewegungen zentral zu erfassen, entsprechend zu steuern und eine Übersicht darüber zu erhalten, wie die Daten verwendet werden. Um diese Aufgabenstellung umsetzen zu können, umfassen DLP-Lösungen Scanning-Mechanismen für eine detaillierte Dateninhaltsanalyse, eine zentrale Regelwerksverwaltung und die Möglichkeit der Erfassung und automatischen Klassifizierung sämtlicher Datenbestände auf Server, Netzlaufwerken, End Points und Cloud-Umgebungen. DLP-Lösungen steuern somit den gesamten Lifecycle der Unternehmensdaten. Das hört sich zunächst nach sehr hoher Komplexität und einem weiteren Level von Bürokratie an. Aber ein Verständnis darüber, was als schützenswert zu betrachten ist, vereinfacht die gesamte IT-Security-Strategie und minimiert von Beginn an das Risiko eines Datenverlustes. Die erfolgreiche Einführung einer DLP-Lösung lässt sich über einen Best-Practice-Ansatz angehen, der sich im Wesentlichen über zwei Schritte definiert und mit den folgenden Fragestellungen verknüpft ist:
1. Erfassung der Daten und Datenanalyse
- Welche Daten sind schützenswert und wo liegen diese?
- Welche Datentypen liegen vor?
- Wie erfolgt eine Klassifizierung schon existierender Datenbestände, die sich nicht mehr ändern?
- Wie und von wem erfolgt die Klassifizierung von aktuellen Dokumenten und Dateien?
- Welche Klassifizierungsklassen sollen eingeführt werden?
2. Datenschutz
- Wer soll Zugriff auf sensible Daten erhalten?
- Welche Kontrollmechanismen stehen für die Einhaltung von Richtlinien im Umgang mit klassifizierten Daten zur Verfügung?
- Wie und wann erfolgt die Aufhebung beziehungsweise Deklassifizierung der Daten?
Erfassung der Daten und die Datenanalyse. Betrachten wir zunächst die Erfassung der Daten und die Datenanalyse. Die große Menge an schon existierenden und historischen Daten verbietet eine manuelle Durchforstung und Klassifizierung und wäre zudem mit zu hohen Fehlerraten behaftet. Automatisiert arbeitende Klassifizierungstools sind hier der einzig gangbare Weg. Es gibt unterschiedliche Verfahren, um historische Datenbestände einem Dokumententypus zuzuordnen und mit einer Klassifizierung zu versehen.
Ältere Verfahren nutzen Profile mit umfangreichen Beschreibungen von Dateiinhalten. Die Datenbestände werden dann gegenüber diesen Profilen gematched, entsprechend kategorisiert und klassifiziert. Neuere Ansätze nutzen »selbstlernende« Verfahren anhand von Beispieldateien, um die Datentypzuordnung und Klassifizierung vorzunehmen. Hierdurch ist es möglich, erhebliche Aufwandsreduzierungen zu erzielen. Gleichzeitig können Graubereiche in der Zuordnung vermieden werden. Da eine Datenklassifizierung auf allen Medien stattfindet, ergibt sich auch ein Lagebild, wo genau schützenswerte Daten liegen. Diese lassen sich später bei Bedarf auf die entsprechend gesicherten Systeme transferieren. Die Klassifizierung von Daten kann nicht mehr über Klassifizierungsautomatismen erfolgen, wenn Daten von Mitarbeitern aktuell genutzt und verändert werden oder im Unternehmen zirkulieren. Hier ist die Unterstützung der Mitarbeiter erforderlich, die Informationen im Unternehmen bereitstellen. In der Regel wird ein »Informationsverantwortlicher« oder »Data Owner« definiert. Typischerweise gehört er der Bereichs-, Abteilungs- oder Projektleitung an oder hat übergreifende Aufgaben (Informationssicherheit, Arbeitsschutz, Datenschutz). Er legt den Kreis der Nutzer (interne und externe Personen) oder die entsprechenden Positionen sowie deren Berechtigungen fest. Die Verantwortlichkeit zur Klassifizierung von Informationen kann durch ihn auch an andere Mitarbeiter delegiert werden. Die Aufgabe der Klassifizierung geht dann an den Verfasser beziehungsweise Dokumentenersteller über.
Es ist ratsam, Schulungen von Klassifizierungsrichtlinien regelmäßig anzubieten und zu wiederholen. Als ein effektives Mittel hat sich E-Learning etabliert. Anhand konkreter Beispiele wird die Sinnhaftigkeit von Datenklassifizierung vermittelt und über die Zeit entwickeln die Mitarbeiter eine gewisse Sensibilität für den richtigen Umgang mit Unternehmensinformationen.
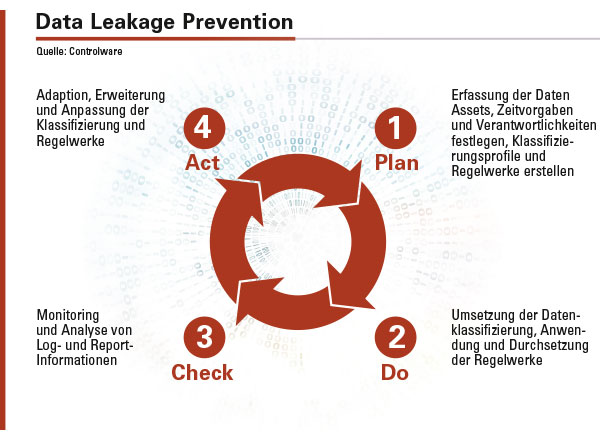
Die vier Stufen der Klassifizierung von Daten und die Anwendung von Regelwerken auf Daten.
Es empfiehlt sich, zunächst mit nur 3 Klassifizierungsklassen zu starten: Public, Private, Restricted. Die anfängliche Reduzierung auf wenige Klassen vereinfacht die Einführung von DLP erheblich. Sollten später feinere Abstufungen notwendig werden, so liegen bereits Erfahrungen im Umgang mit Datenklassifizierung vor und es wurde eine fundierte Basis geschaffen, auf der aufgebaut werden kann.
Datenschutz. Wenden wir uns nun dem Datenschutz zu. Eine strukturelle Vorgehensweise zum Datenschutz lässt sich finden, wenn Daten in ihrer Dynamik erfasst werden. Daten liegen beispielsweise auf Servern, Netzlaufwerken, in der Cloud (Data at Rest) oder Daten werden gerade im Unternehmen transferiert (Data in Motion) beziehungsweise werden gerade von Anwendern verwendet (Data in Use). Eine Unterteilung macht deshalb Sinn, da für die jeweiligen dynamischen Kategorien unterschiedliche technische Konzepte den effektiven Schutz der Daten gewährleisten. Mit diesem Ansatz werden alle Daten erfasst – unabhängig vom Daten- oder Medientyp.
Data at Rest. Daten, die auf Servern, Storage-Systemen, Netzlaufwerken oder in der Cloud liegen, werden über die Content-Analyse-Tools der DLP-Lösung einer Inhaltsanalyse unterzogen. Zum Beispiel können Dokumente auf Kreditkarten-Formate oder Texte auf die Wörter »vertraulich, geheim, intern only etc.« gescannt und dementsprechend mit einem Label versehen werden. Damit lässt sich sehr leicht klären, wo sensible Daten liegen und ob diese auch an diese Stelle gehören.
Data in Motion. Generell bieten Datenklassifizierungslösungen eine Integration in die gängigen Groupware-,
E-Mail- und Instant-Messaging-Anwendungen, um ein versehentliches Versenden von als vertraulich eingestuften Dokumenten an nicht autorisierte Personenkreise zu verhindern. Hier greifen die zentralen Regelwerke der DLP-Lösung und kontrollieren vor dem Versand oder Download, ob der Empfängerkreis autorisiert ist beziehungsweise ob das Medium genutzt werden darf.
Es ist ratsam, Daten, die über Unternehmensnetze transferiert werden, zusätzlich über Data-Leakage-Funktionen von Security-Gateways oder DLP Add Ons von Netzwerksensoren/ Intrusion Prevention-Systemen auf sensible Inhalte zu überprüfen. Die DLP-Funktionen dieser Hersteller stellen in der Regel einen sehr kostengünstigen erweiterten Schutz vor unerlaubtem Datentransfer (E-Mail, Downloads, Instant-Messaging, Social Media) dar.
Data in Use. Eine DLP-Lösung wäre nicht komplett, wenn sie nicht auch den End Point und den Dokumentenersteller einbeziehen würde. Auf den Endgeräten werden die meisten Dokumente erstellt, gespeichert und versendet. Hier liegen demzufolge die größten Herausforderungen, einen effektiven Schutz zu gewährleisten. Wie schon angesprochen, erfolgt die Integration der Funktionen von DLP-Lösungen in die normalen Büroanwendungen so, dass Nutzer keinen erhöhten Aufwand bei der Erstellung oder dem Versand der Daten haben. Beispielsweise müssen alle Dokumentenersteller vor dem Speichern eines Dokumentes eine entsprechende Klassifizierung vornehmen. Eine Speicherung ohne Klassifizierung ist normalerweise nicht möglich. Beim Versand per E-Mail erfolgt automatisch ein Abgleich, ob der Inhalt der E-Mail und der zugehörigen Anhänge mit der Vertraulichkeitsstufe des Empfängers übereinstimmen. Als »vertraulich/restricted« oder »nur für den internen Gebrauch« klassifizierte Dokumente werden entsprechend den Regelwerken automatisch verschlüsselt. Darüber hinaus können auch Wasserzeichen in den Dokumenten hinterlegt werden, um die Authentizität des Senders zu bestätigen. Beim Druck der Dokumente weist das Wasserzeichen für alle sichtbar auf die Vertraulichkeitsstufe hin.
Lösungen von End-Point-Security-Anbietern können hier erweiterten Schutz bereitstellen, indem diese den Medienzugriff generell kontrollieren. So lässt sich sicherstellen, dass beispielsweise nur zertifizierte USB-Sticks Verwendung finden oder Dateien vor dem Aufspielen auf externe Speichermedien prinzipiell verschlüsselt werden. Vor dem Transfer erfolgt ein Scanning der Daten auf sensible Inhalte – gegebenenfalls wird der Transfer ganz unterbunden.
Da Datenbestände an Aktualität verlieren, verändern sich zwangsläufig auch die jeweiligen Einstufungen. Das bedeutet, dass beispielsweise Daten, die zunächst eine hohe Vertraulichkeitsstufe rechtfertigten, diese über die Zeit verlieren können. Es ist deshalb sinnvoll, Datenbestände hinsichtlich ihres Schutzlevels regelmäßig zu überprüfen und entsprechend anzupassen. Daten, die aufgrund rechtlicher Vorgaben über längere Zeiträume gespeichert werden müssen, sollten ihren Vertraulichkeitslevel beibehalten, um Revisionssicherheit zu garantieren. Grundsätzlich ist es von Vorteil, auch Daten zu löschen, wenn ihr Wert für das Unternehmen nicht mehr erkennbar ist. Dies sorgt für eine bessere Übersicht existierender Datenbestände und unnötiges Datenvolumen lässt sich so recht einfach reduzieren.
Fazit. Wichtig ist, Data Leakage Prevention als Kernbaustein einer effektiven IT-Security-Strategie zu verstehen. Die Schaffung von Sichtbarkeit und Transparenz in Bezug auf die eigenen Datenbestände erhöht auch bei den Mitarbeitern die Sensibilität für das Thema Datenschutz. Investitionen in die IT-Security können sich primär am Schutz dieser Datenbestände ausrichten. Mittlerweile stehen ausgereifte DLP-Lösungen zur Verfügung, um Projekte ohne hohen Aufwand erfolgreich umzusetzen.
DLP-Teilfunktionen von Anbietern klassischer Security-Gateways oder End-Point-Lösungen stellen eine sinnvolle Ergänzung zu einer ganzheitlichen DLP-Strategie dar, denn sie reduzieren ebenfalls das Risiko eines Datenverlustes.
Für die Umsetzung von DLP-Projekten ist es auf jeden Fall ratsam, externe Security-Experten einzubeziehen. Als Systemintegrator und Managed Service Provider mit themenübergreifendem Know-how und langjähriger Erfahrung ist Controlware hier der ideale IT-Partner.
 Rainer Funk,
Rainer Funk,
Solution Manager
Information Security,
Business Development
www.controlware.de
[1] SANS Institut – Understanding and Selecting a DLP Solution 2015
[2] Forrester Reseach 2015: The Future of Data Security and Privacy
Illustration: © NickKimney/shutterstock.com
Hier folgt eine Auswahl an Fachbeiträgen, Studien, Stories und Statistiken die zu diesem Thema passen. Geben Sie in der »Artikelsuche…« rechts oben Ihre Suchbegriffe ein und lassen sich überraschen, welche weiteren Treffer Sie auf unserer Webseite finden.
Europäische Datenschutzgrundverordnung: Drei Tipps für die Cloud-Nutzung in Unternehmen
Skalierbare Sicherheitslösungen bieten Schutz und Transparenz
Arbeitsmarktstudie 2016: IT-Sicherheit mit größtem Stellenaufbau bis 2020