
Der Begriff Big Data Analytics bezeichnet ein umfangreiches Spektrum von Methoden und Verfahren, beispielsweise Datenintegration, Datenmanagement, Business Intelligence und Predictive Analytics. Sie alle verfolgen das Ziel, eine breite Datenbasis möglichst effizient zur Optimierung von Entscheidungsprozessen im Unternehmen einzusetzen. Eine wichtige Rolle dabei spielt eine kontinuierlich hohe Datenqualität, ohne die keine echten Fortschritte erreichbar sind und im schlimmsten Fall das Risiko besteht, falsche Schlüsse zu ziehen.
An Daten herrscht in den Unternehmen kein Mangel, ganz im Gegenteil. Nicht umsonst klagen viele sogar über eine Datenflut. Während bei den Daten aus transaktionalen Systemen (etwa ERP- oder CRM-Systeme), die vorwiegend in relationalen Datenbanken abgelegt werden, lediglich ein moderates Wachstum zu verzeichnen ist, ergibt sich vor allem durch die Integration von Daten aus neuen Datenquellen (Stichwort »Big Data«) wie Bildern, Dokumenten, Videos, Sensoren-Streams und Informationen aus sozialen Netzwerken, ein massives Wachstum. Entscheidend ist, wie Unternehmen die Informationen nutzen, um wichtige Entscheidungen vorzubereiten.
Alles, was mit Analytics zu tun hat, gewinnt weiter an Bedeutung und wird zu einem Wettbewerbsfaktor. Analysen stellen die benötigten Informationen für Entscheidungen bereit. Gleichzeitig haben sich Unternehmen im Bereich Analytics auf der Stufenleiter immer weiter vorgearbeitet. Während sich einige noch auf beschreibende (was ist geschehen?) und interpretierende (warum ist etwas geschehen?) Analysen beschränken, sind andere schon weiter. Sie befassen sich mit prognostischen Analysen und wollen wissen, was passieren wird.
Zugegeben: Predictive Analytics als zentrales Einsatzgebiet von Big Data Analytics ist nicht ganz neu und Beispiele für prognostische Analysen gibt es viele. Online-Shops präsentieren Interessenten eine Liste mit Komplementärprodukten und berechnen dafür die Kaufwahrscheinlichkeit. Mit Hilfe von Prognosemodellen optimieren Unternehmen aus dem produzierenden Gewerbe zum Beispiel die ein- und ausgehenden Warenströme sowie die Maschinenauslastung in der Fertigung oder verwenden ein vernetztes System von Sensoren, das die Verfügbarkeit, Zuverlässigkeit und Reparaturwahrscheinlichkeit von Maschinen ermittelt. Logistikunternehmen berechnen Modelle, um ihre Tourenplanung weiter zu verfeinern. In Marketing und Vertrieb finden sich Anwendungsszenarien von prognostischer Analytik, die zu mehr Transparenz über das Kundenverhalten führen und eine individuellere Ansprache ermöglichen sollen.
Ein Predictive-Analytics-Projekt ist nie abgeschlossen. Auch wenn es eine beträchtliche Zahl von Berichten über Predictive-Analytics-Projekte gibt, befinden sich noch viele in einem frühen Stadium. In einigen Fällen hat man mit zu starren Prognosemodellen für isolierte Umgebungen begonnen. Als sich im Laufe der Zeit die Anforderungen an die betrieblichen Entscheidungsprozesse änderten, konnten die Modelle nicht mehr Schritt halten und diverse Projekte wurden eingefroren und andere ganz beendet.
Predictive-Analytics-Projekte sind nur dann erfolgreich, wenn all ihre Methoden, Verfahren, technologischen und organisatorischen Grundlagen permanent weiterentwickelt werden und die berechneten Prognosen kontinuierlich gegen das eintretende IST verifiziert werden. Die Lernfähigkeit der eingesetzten Prognosemodelle ist dabei einer der zentralen Punkte. Wird die Datenbasis für das Modell verbreitert – das heißt, zusätzliche Datenquellen werden mit einbezogen – sollte das Modell in der Lage sein, die Prognosegenauigkeit zu erhöhen. Wichtig ist dies zum Beispiel im Kundenmanagement, wo täglich neue Daten entstehen. In diesem Umfeld kommt seit einiger Zeit beispielsweise das NeuroBayes-Modell zum Einsatz, das ursprünglich am Genfer CERN entwickelte wurde, um das Verhalten von Quanten vorauszusagen.
Wenn es um die Analyse und Vorhersagen des Kundenverhaltens geht, sollten den Erfahrungen von CGI zufolge Prognosemodelle auch Optionen bieten, um die Ergebnisse von Text- und Social-Media-Analytics zu integrieren. Auch hier geht es darum, die Prognosefähigkeit zu verbessern, indem unter Einbeziehung weiterer verfügbarer Informationen exaktere Prognosen möglich werden. Die besten Prognosemodelle nützen jedoch nichts, wenn die Datenqualität nicht stimmt und es keine Leute gibt, die die Daten fachmännisch auswerten und inhaltlich bewerten können.
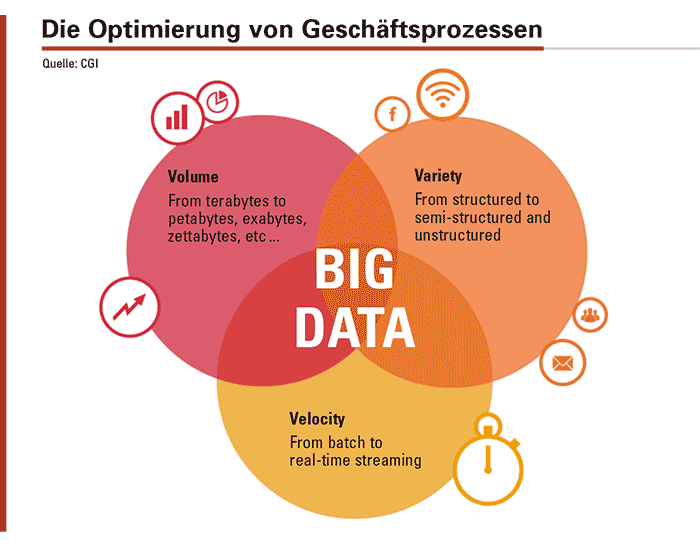
Big Data Analytics befasst sich mit der Optimierung von Geschäfts- prozessen und verwendet dazu aggregierte Informationen aus den unterschiedlichsten Datenquellen.
Gute Datenqualität zahlt sich aus. Die Grundlage aller Aktivitäten bei Big Data Analytics ist die dafür verwendete Datenbasis und deren Qualität. Ob die Bestände den Anforderungen an eine hohe Datenqualität genügen, lässt sich mit Hilfe verschiedener Kriterien ermitteln: Aktualität, Eindeutigkeit, Einheitlichkeit, Genauigkeit, Konsistenz, Korrektheit, Redundanzfreiheit, Relevanz, Verständlichkeit, Vollständigkeit und Zuverlässigkeit. Die Datenqualität ist ausschlaggebend für die Aussagekraft der Ergebnisse prognostischer Analysen.
Eine der zentralen Herausforderungen besteht darin, dass es in vielen Unternehmen keine konsistente Datenbasis gibt und oft verschiedene Abteilungssilos sowie unterschiedliche Definitionen von Meta-Daten existieren. So ist beispielsweise ein Kunde in Abteilung A nicht unbedingt ein Kunde in Abteilung B, denn die Abteilung A zählt alle Kunden, mit denen man in den letzten zehn Jahren einen Umsatz tätigte. Die Abteilung B dagegen erfasst alle aktiven Kunden, mit denen im letzten Jahr ein Kontakt bestand und mit denen mindestens ein Umsatz von xy Euro erzielt wurde. Aufgrund der unterschiedlichen Definitionen sind keine sinnvollen Vergleiche möglich. Noch schwieriger kann sich die Lage gestalten, wenn in einem internationalen Konzern nicht nur lokale Abteilungssilos bestehen, sondern auch noch die Besonderheiten diverser Ländergesellschaften hinzukommen.
- Um zuverlässige und handlungsrelevante Erkenntnisse zu gewinnen, ist der Zugriff auf eine breite Datenbasis erforderlich. Wichtig sind Daten aus drei großen Segmenten:
- Strukturierte Daten beispielswiese zu Kunden, Aufträgen oder Produkten, die vorwiegend aus transaktionalen Systemen stammen.
- Unstrukturierte Daten wie aus Web-Klick-Streams, Social-Media-Plattformen oder Sensoren.
- Externe Daten in Form von Geo-Informationen, Wetterwerten oder Informationen von Marktforschungsunternehmen.
Eine zentrale Rolle in diesem Zusammenhang spielt die Data Governance. In der Praxis geht es in erster Linie nicht darum, ob die Daten hundertprozentig valide und vollständig sind. Entscheidend ist vielmehr, dass die Analysten und Entscheider sich ein Urteil über die Güte und Beschaffenheit der Daten bilden. Beim traditionellen Reporting und bei Analyseszenarien, die regulatorische Anforderungen betreffen, müssen Daten absolut korrekt sein. Dagegen sind bei Trendanalysen, die einen Ergebniskorridor ermitteln, oder der Nutzung von Durchschnittswerten, etwa der mittleren Monatstemperatur 2014 in allen Bundesländern, Unschärfen, die durch statistische Methoden ausgeglichen werden können, durchaus akzeptabel.
Eine hohe Datenqualität, wie sie für operative Big-Data-Analytics-Aktivitäten benötigt wird, lässt sich nur durch ein systematisches, unternehmensweites Vorgehen erzielen. Notwendig ist dazu eine kontinuierliche Zusammenarbeit zwischen den Fachbereichen und der IT, denn letztere muss das technologische Fundament für die Arbeit der Analysen bereitstellen. Eine der Varianten besteht darin, in einem Competence Center Mitarbeiter aus der IT und den Fachbereichen zusammenzubringen, die für eine beständig hohe Datenqualität zuständig sind. Einige Unternehmen haben gute Erfahrungen mit Data Stewards gesammelt. Ähnlich wie ein Process Owner, der für die Steuerung und Überwachung eines Geschäftsprozesses zuständig ist, verantwortet der Data Steward die Datenqualität für einen bestimmten Bereich.
Aber auch die Anforderungen an die Big-Data-Analysten beziehungsweise die Data Scientists steigen. Sie benötigen gute IT-Kenntnisse, müssen die statistischen und stochastischen Verfahren, inklusive der mathematischen Grundlagen, beherrschen und sollten auch den Mut zu Experimenten haben, um neue Wege auszuprobieren. Eine wichtige Rolle dabei spielt die Technik, die es ermöglicht, neue Zusammenhänge zu erkennen, mit den Kollegen in den Fachbereichen deren Handlungsrelevanz zu testen und die Genauigkeit und Gültigkeit von Vorhersagen zu überprüfen und weiterzuentwickeln. Das ist eine Voraussetzung, um die Potenziale von Predictive Analytics optimal zu erschließen.
Die Rolle eines IT-Dienstleisters wie CGI besteht darin, die Kombination der fachlichen Expertise bei Kunden mit dem eigenen technischen und methodischen Know-how in konkrete Projekte einzubringen. Hinzu kommt der technische Fortschritt in der IT in den letzten Jahren, der neue Möglichkeiten bietet. Zu nennen sind hier die Vervielfachung der Prozessorleistung, der günstigere Speicherplatz, die stärkere Verbreitung von In-Memory-Datenbanken und intuitiv zu bedienende Analyse-Tools wie Heatmaps oder geografische Darstellungen. Während es früher oft mehrere Stunden dauerte, um verschiedene Szenarien zu berechnen, ist dies heute innerhalb weniger Minuten möglich. Die Genauigkeit von Prognosen lässt sich damit spürbar steigern. Für Unternehmen bedeutet dies, dass sie mit den gewonnenen Erkenntnissen ihre Wettbewerbsfähigkeit stärken können. In einem Markt, der durch Endkunden getrieben ist und in dem Kunden über umfassende Informationen verfügen, ist dies entscheidend, um das Kaufverhalten erfolgreich beeinflussen zu können.
 Knut Veltjens ist
Knut Veltjens ist
Vice President / Practice Head
Business Intelligence bei CGI
in Sulzbach bei Frankfurt am Main