

foto freepik
Wenn man die Nachrichten im Bereich Deep Learning verfolgt, hat man sicher zur Kenntnis genommen, dass die Daten und Modelle im Bereich Deep Learning inzwischen sehr groß sind. Die Datensätze können in der Größenordnung von Petabytes liegen, und die Modelle selbst sind ebenfalls Hunderte von Gigabytes groß. Das bedeutet, dass nicht einmal das Modell selbst in den Speicher eines Standard-GPU-Chips passen würde. Effiziente und intelligente Parallelisierung sowie die Wiederherstellbarkeit von Daten sind in der Welt des Deep Learning also von höchster Bedeutung.
Colleen Tartow, Field CTO und Head of Strategy bei VAST Data, erläutert die Herausforderungen für Speicherumgebungen durch wachsende Large Language Models und deren Bewältigung:
Bei den großen Datensätzen und großen Modellen, die in Large Language Models (LLMs) und in anderen Deep-Learning-Algorithmen in besonderem Maßstab verwendet werden, sind sowohl die Daten als auch die Modelle selbst zu umfangreich, um in den Speicher zu passen. So passt beispielsweise ein typisches LLM mit seinen Milliarden von Hyperparametern nicht in den Arbeitsspeicher. GPT-3 ist mehr als 500 Gigabyte groß, und eine typische GPU ist auf 80 Gigabyte von Virtual Memory (VMEM) beschränkt. Darüber hinaus würde die serielle Ausführung eines LLMS beträchtliche Zeit in Anspruch nehmen: Ein einziger A100-GPU-Server würde Hunderte von Jahren für das Training eines LLMs benötigen. Daher ist die mehrdimensionale Parallelität für das Training und die Feinabstimmung von Modellen entscheidend.
Diese Argumente stützen sich auf umfangreiche Forschungsarbeiten auf diesem Gebiet, insbesondere auf die bahnbrechende Arbeit »Large-Scale Training with Megatron-LM« von Stanford, NVIDIA und Microsoft Research. Die Autoren schlagen dort vor, dass eine Synthese aus drei Arten von Parallelität eine viel besser zu bewältigende und wiederherstellbare Arbeitslast in LLMs ermöglicht:
- Data Parallelism: Das gesamte Modell wird auf mehrere GPUs oder CPUs repliziert und die Trainingsdaten werden auf diese verteilt. Dies ist die einfachste und gebräuchlichste Art der Parallelität, aber bei großen Modellen ist sie in der Regel extrem speicherintensiv.
- Model Parallelism: Das Modell selbst wird in diskrete Schichten oder Tensoren zerlegt und dann auf mehrere GPUs oder CPUs verteilt. Dies kann recht komplex in der Implementierung sein, ist aber speichereffizienter als Datenparallelität.
- Pipeline Parallelism: Der Prozess der Modellbildung wird in kleinere Schritte zerlegt und auf verschiedenen GPUs oder CPUs ausgeführt. Dies kann die Latenzzeit erhöhen oder das Modell besonders serialisieren, kann aber bei guter Ausführung den Trainingsdurchsatz verbessern.
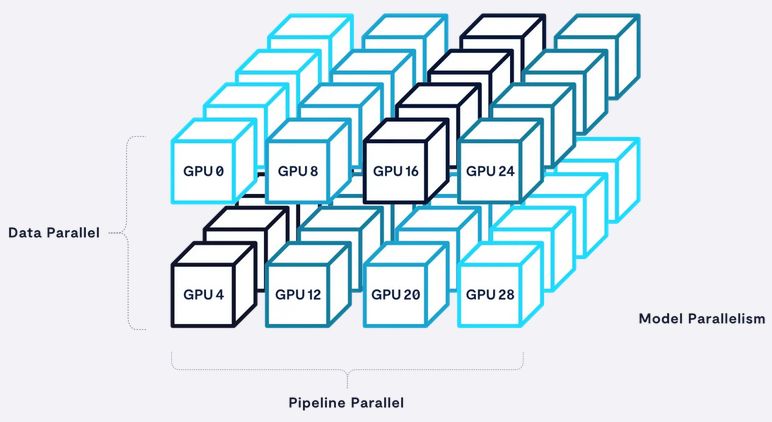
Quelle: VAST Data
Durch die Kombination der drei Haupttypen von Parallelität kann die gesamte Performance des Modelltrainings gleich um mehrere Größenordnungen gesteigert werden.
Checkpoints und Wiederherstellbarkeit
Sobald ein Modell parallelisiert ist, kann es immer noch einen Monat oder länger dauern, bis ein Trainingsauftrag vollständig ausgeführt ist. Daher ist die Wiederherstellbarkeit der Ausführung des Modells ein entscheidender Faktor, und es sollten regelmäßige Checkpoints des Systemzustands erstellt werden. Normalerweise werden Checkpoints nach jeder Trainingsepoche (das heißt nach einem vollständigen Durchlauf des Trainingsdatensatzes) gesetzt.
Alternativ kann es auch notwendig sein, einen Schritt zurück zu gehen und die Hyperparameter eines Modells in der Mitte des Prozesses zu ändern. Das Checkpointing würde diese Änderung ermöglichen, ohne dass ein vollständiger Modelllauf von Anfang an erforderlich wäre. Darüber hinaus ist Checkpointing für die Wiederholbarkeit von Modellen von entscheidender Bedeutung.
Aus diesem Grund ist es äußerst wichtig, dass eine AI-Architektur so konzipiert ist, dass sie Checkpoint-Operationen in angemessener Weise ermöglicht. Man sollte beachten, dass AI-Modelle selbst in der Regel nicht I/O-gebunden sind, sondern GPU-gebunden bleiben.
Dimensionierung von Checkpoints: Sprechen wir in Zahlen
Die Dimensionierung der Infrastruktur war in den letzten Jahren ein häufiges Gesprächsthema, da immer mehr AI-Technologien auf den Markt kamen. Daher ist GPT-3 das perfekte Beispiel, um zu erörtern, wie die Infrastruktur für Deep Learning im Allgemeinen und LLMs im Besonderen angemessen bereitgestellt werden kann. Gehen wir dieses Beispiel durch und rechnen wir aus, wie ein solches System zu dimensionieren ist:
- GPT-3 hat 175 Milliarden Hyperparameter, und nehmen wir an, dass wir alle drei Arten der Parallelität bei der Bereitstellung dieses LLMs verwenden werden und dass wir es auf 1.024 Grafikprozessoren bereitstellen werden, was 128 NVIDIA DGX-A100-Maschinen entspricht (jede enthält 8 Grafikprozessoren).
- Wie bereits erwähnt, ist das ~500 Gigabyte große Modell selbst zu groß, um in den 80 Gigabyte großen Speicher eines einzelnen Grafikprozessors zu passen. Daher verwenden wir tensor-basierte Modellparallelität, um das Modell auf die 8 Grafikprozessoren in einem DGX-Node zu verteilen.
- Um die Pipeline-Parallelität zu implementieren, wird das Modell auf Gruppen von 8 DGXs oder Oktetts repliziert. Man beachte, dass das hier beschriebene Pipeline-Parallel-Oktett in sich geschlossen ist und das gesamte Modell und die Pipeline für ein LLM enthält. Daher muss nur ein Oktett pro System geprüft werden, unabhängig von der Gesamtgröße des Clusters, da es eine vollständige Darstellung des Systems ist.
- Jede GPU wird daher als 1 Thread bereitgestellt, 8 Threads pro 8-GPU DGX und 64 Threads pro 8-DGX-Oktett. Dies führt zu gepufferten sequenziellen Schreibvorgängen für große Blöcke, die in eine Prüfpunktdatei pro Thread geschrieben werden.
- Schließlich parallelisiert man die Daten in 16 Gruppen von 8 pipeline-parallelen Systemen (128 Nodes).
Die Kombination aus Tensor-Modell, Pipeline und Datenparallelität ermöglicht eine lineare Skalierung im Megatron-Muster bis hin zu Modellen mit 1 Billion Parametern und einer Flop-Effizienz von nahezu 50 Prozent der theoretischen Werte.
Die Quintessenz dieses Beispiels besteht darin, dass die Größe eines Checkpoints überhaupt nicht von der Größe der Daten oder der Anzahl der GPUs abhängt, sondern nur von der Größe des Modells. Bei der Bereitstellung der Infrastruktur für LLMs besteht die einzige Überlegung in Bezug auf das Checkpointing darin, die Größe der Modelle zu kennen, die man einsetzen wird, und dann sicherzustellen, dass genügend Bandbreite vorhanden ist, um Checkpoints zu schreiben und einen Checkpoint zu lesen, wenn die E/A-Grenzen erreicht sind.
Wie lange dauert ein Wiederherstellungsvorgang?
Die für die Wiederherstellung benötigte Lesebandbreite ergibt sich aus der Datenparallelität (6 in diesem Beispiel) multipliziert mit den Schreibvorgängen, also 6×273 Gigabyte/s= 1.638 Terabyte/s. Die Schreibbandbreite beträgt 17 Prozent der für die Wiederherstellung erforderlichen Lesebandbreite. Solange ein Speichersubsystem 1,64 Terabyte/s für Lesevorgänge und 280 Gigabyte/s für Schreibvorgänge liefern kann, ist die Checkpoint-Zeit optimal und entspricht etwa 50 Sekunden für einen 13,8-Terabyte-Modellzustand.
Der Checkpoint für Checkpoints
In letzter Zeit wurde auf dem Markt auch darüber diskutiert, dass ein System für Checkpoints 1 Gigabyte/s pro GPU für alle GPUs im Cluster benötigt. Klar ist, basiert dies nicht auf realistischen Berechnungen. Wie gezeigt wurde, sind für einen Checkpoint-Vorgang nicht mehr als 8 Gigabyte/s pro DGX in einem Oktett erforderlich. Daher muss nicht jede GPU zur gleichen Zeit einen Checkpoint durchführen, wodurch eine Überbelegung der Speicher-Hardware für solche Trainings-Cluster vermieden wird.
Man sollte daran denken, dass ein Checkpoint nicht absolut alles im System widerspiegeln muss. Er muss lediglich eine kohärente Aufzeichnung des Zustands eines Systems sein, von der aus man dieses System wiederherstellen kann. Mit anderen Worten: Man muss einen Snapshot des Modells und der Pipelines in einem konsistenten Zustand erstellen. Es ist wichtig zu erkennen, dass dies nicht von den Daten abhängt, sondern nur von den Gewichtungen und Verzerrungen, die im aktuellen Zustand des Modells vorhanden sind.
[1] https://arxiv.org/pdf/2104.04473.pdf