Ein Data Warehouse (DWH) sollte neue Daten schnell zur Verfügung stellen können. Auch oder gerade, wenn sich Anforderungen ändern, neue Anwendungen weitere Daten liefern oder gar unstrukturierte Daten integriert werden müssen. Gleichzeitig sollten die Daten häufiger geladen werden: täglich oder mehrfach täglich.
Dem steht entgegen, dass die Integration der Daten ihre Zeit braucht. 80 Prozent der Aufwände fallen für Tätigkeiten an, die der Business-User nicht sieht, wie Datenkorrektur, Datenkonsolidierung oder Berechnen von Werten, die im Dialogsystem nicht gespeichert wurden.
Sucht man nach einer Lösung für dieses Dilemma, lautet die Antwort seit 20 Jahren: »Verwenden Sie bessere und schnellere Systeme!«. Tatsächlich sind in den letzten Jahren einige neue BI-Lösungen auf den Markt gekommen. Mit NoSQL-Datenbanken, DB Appliances und Self Service BI lassen sich bereits erhebliche Verbesserungen erzielen.
Herausforderung bleibt, die Daten zu integrieren und zu konsolidieren. Diese Aufgaben machen den Löwenanteil an Aufwänden aus; die neuen Lösungen tragen wenig dazu bei, diese zu reduzieren. Dank Self Service BI sind Business-User in der Lage, ihre Daten selbst zu integrieren und zu konsolidieren, ohne Unterstützung durch die IT. Nichtsdestotrotz braucht es eine gemeinsame Basis auf der Daten ausgewertet werden können. Wenn jede Abteilung eigene Regeln aufstellt, sind zwei Berichte desselben Inhalts nicht miteinander vergleichbar.
Methodik statt Werkzeuge. Was also tun, wenn sich durch die Verwendung neuer Werkzeuge nur ein Teil der Herausforderung bewältigen lässt? Hier ist es sinnvoll, bei der Methodik anzusetzen. Data Vault – 2001 von Dan Linstedt begründet – ist eine in Deutschland noch relativ unbekannte Methodik, um Daten im Data Warehouse aufzubereiten und zu modellieren. Sie vereinfacht und beschleunigt die Erstellung der Datenaufbereitungsprozesse. Änderungen können leichter vorgenommen werden und haben geringere Auswirkungen.
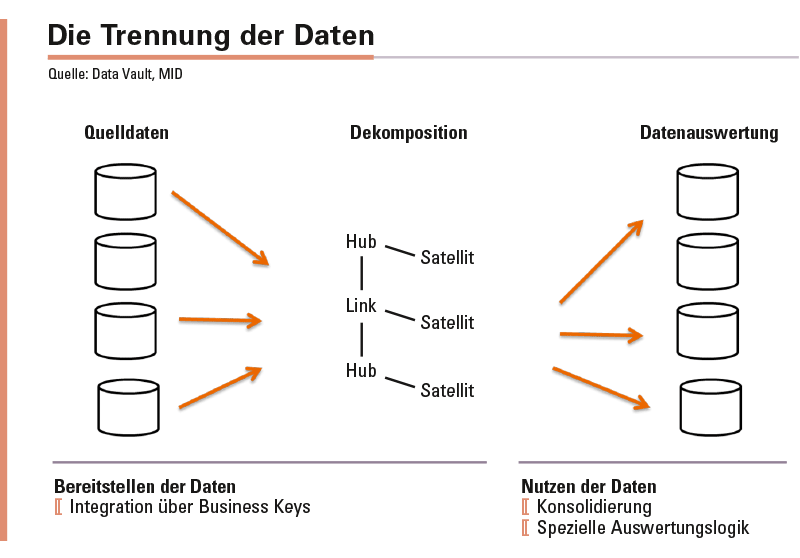
Trennung von Integration und Aufbereitung. Bei Data Vault werden Integration und Aufbereitung der Daten getrennt, was die Komplexität von Auswertungen reduziert. Zunächst werden die Daten in ein einheitliches Format gebracht und miteinander verknüpft – ohne jedwede Konsolidierungslogik. Erst von diesem allgemeinen Format aus findet dann die Aufbereitung zur Auswertung statt. So stehen die Daten in der Rohform bereit und können je nach Anforderung aufbereitet werden. Selbst unterschiedlichste Aufbereitungswünsche können auf einen gemeinsamen Ursprung zurückverfolgt werden.
Trennung in Geschäftsobjekte, Transaktionen und Attribute. Damit kommt dem allgemeinen Format eine zentrale Bedeutung zu. Es trennt die Daten in Geschäftsobjekte wie Kunde, Produkt, Auftrag. Für diese gibt es eindeutige Schlüssel im Unternehmen (Business Keys), welche in einem sogenannten Hub hinterlegt werden. Auf Basis dieser Geschäftsobjekte finden Transaktionen statt, etwa Erteilung eines Auftrags, die über einen »Link« verknüpft werden. Alle Attribute, die einen Hub (Geschäftsobjekt) oder einen Link (Transaktion) beschreiben, landen in Satelliten. Satelliten sind Tabellen, die mit dem Hub beziehungsweise Link verknüpft werden.
Somit sind alle Daten in drei Klassen unterteilt, die sich nun wie Legosteine zusammensetzen lassen. Mehr wird für die Integration der Daten nicht benötigt; es entsteht ein Bild der Unternehmensdaten »wie sie sind«. Dieses Bild dient als zentrale Basis für alle gewünschten Auswertungen, widersprüchliche Analysen in unterschiedlichen Reports lassen sich schnell klären.
Die Muster der Dekomposition bieten weitere Möglichkeiten. Die Dekomposition, also Trennung, der Daten in Hub (Geschäftsobjekt), Link (Transaktion) und Satellit (Attribute) erfolgt nach klaren Mustern. Diese können dazu genutzt werden, die Erstellung der Aufbereitungsprozesse zu automatisieren. Wenn jeder Hub der gleichen Logik folgt, muss diese nur einmal implementiert werden. Das ermöglicht deutliche Geschwindigkeitsgewinne in der Entwicklung des DWH durch Automation.
Die Erstellung einer Auswertung auf Basis von Hub, Link und Satellit kann ebenfalls nach Mustern und automatisiert erfolgen. Gepaart mit der Möglichkeit die Daten in ihrer Rohform – das heißt ohne weitere Konsolidierungen – an den Business-User weiterzugeben, wird die Zeit bis zur Bereitstellung der Auswertung erheblich verkürzt. Es genügt, die Datenmodelle zu erstellen, die Aufbereitung kann mittels der Metadaten aus den Datenmodellen generiert und die Auswertung umgehend bereitstehen.
Etwaige Bereinigungen der Auswertung können im Dialog mit dem Business-User vorgenommen werden. Das reduziert die Gefahr von Fehlentwicklungen und beschleunigt wiederum die Entwicklung. Werden die bereinigten Daten ebenfalls als Hub, Link oder Satellit gespeichert, können auch hier die Muster zur Auswertung greifen. Die Umstellung der Auswertung auf die bereinigten Daten benötigt dann nur minimalen Aufwand.
Die Dekomposition (Trennung) der Daten in Hub (Geschäftsobjekt), Link (Transaktion) und Satellit (Attribute) erfolgt nach klaren Mustern. Dadurch lassen sich die Aufbereitungsprozesse automatisieren und deutliche Geschwindigkeitsgewinne in der Entwicklung des DWH erzielen.
Unabhängigkeit reduziert Änderungsaufwand. Im Data Vault gibt es wenige Abhängigkeiten. Die Satelliten sind von ihrem jeweiligen Hub beziehungsweise Link abhängig; Hubs werden nur über Links verknüpft. Eine Änderung findet immer nur lokal statt; es gibt keine versteckten Abhängigkeiten. So reduziert sich der Änderungsaufwand erheblich und weniger Tests sind nötig, da Änderungen sehr lokal begrenzt sind.
Da es keine direkten Abhängigkeiten zwischen Hubs gibt, lassen sich die Daten unabhängig voneinander laden. Die Entscheidung über den Ladezyklus kann unabhängig vom Rest der Daten erfolgen. Ein täglich oder mehrfach täglich aktualisiertes DWH ist auf Grund der Methodik ohne weiteren Aufwand zu erzielen.
Frischer Wind dank neuer Methode. Viele der hier vorgestellten Mechanismen sind bereits bekannt. Das Neue an Data Vault ist die konsequente Umsetzung und der eindeutige Rahmen, in dem diese Mechanismen zusammenwirken. Die Trennung von Integration und Konsolidierung sowie die Dekomposition auf Basis von Business Keys lösen die Herausforderungen an ein DWH besser als neue Werkzeuge.
Mehr noch, im Zusammenspiel mit den neuen Werkzeugen ergeben sich weitere Möglichkeiten. Die Integration über die Business Keys bietet die gemeinsame Basis, auf der Self Service BI ihre volle Kraft entfalten kann. Die Unabhängigkeit der Daten untereinander bei gleichzeitigem Fokus auf eindeutige Schlüssel ermöglicht eine Verteilung der Daten auf mehrere Plattformen.
 Michael Müller,
Michael Müller,
Principal und BI-Experte
bei der MID GmbH
www.mid.de