Illustration Absmeier foto freepik
In Europa entsteht ein Large Languange Model, das zuverlässiger, offener, transparenter und energiesparender sein soll als ChatGPT. Der Schlüssel dazu ist Europas größter Computer, der derzeit in Jülich gebaut wird.
Seit das amerikanische Unternehmen OpenAI im November 2022 die Sprachmaschine ChatGPT zugänglich machte, geht das Thema durch die Decke. Können jetzt Personaler ihre Zeugnisse, Anwälte ihre Schriftsätze und Programmierer ihre Codes an Sprachmaschinen outsourcen? Die Reaktionen reichen von Panik bis Euphorie.
Unzweifelhaft steckt (künstliche) Intelligenz hinter diesen großen Sprachmodellen (Large Language Model, LLM). Gleichwohl heißt das nicht, dass sie auch intelligent antworten. Wer den Chatbot der Suchmaschine Bing fragt, was LLMs sind, dem antwortet er: »Large Language Models sind leistungsstarke Modelle, die darauf ausgelegt sind, menschliche Sprache zu verstehen und zu generieren. Sie können Text analysieren, kohärente Antworten generieren und sprachbezogene Aufgaben ausführen.« Das entscheidende Wort ist »kohärent«. Das heißt, der Content ist plausibel, die Grammatik korrekt, aber die Fakten müssen nicht stimmen.
Sprachmodelle arbeiten mit künstlichen neuronalen Netzwerken, die von der Funktionsweise des Gehirns inspiriert sind. Wie mit einem virtuellen Nürnberger Trichter wird der Software eine gewaltige Textmenge verabreicht. Die Maschine lernt während des Trainings aus dem Informationsberg, in dem sie nach Muster sucht und darauf basierend neue Inhalte ausgibt. Ob das Ganze stimmt, verraten die Gehirn-Imitate nicht. Sie sagen nur, mit welcher Wahrscheinlichkeit in einem Satz ein Wort auf das andere folgt. Das Ergebnis ist daher nicht frei von Fehleinschätzungen, Manipulationsmöglichkeiten, Verstößen gegen Datenschutz, Urheber- oder und Persönlichkeitsrechten. Gefragt nach der Zuverlässigkeit von ChatGPT antwortet der Chatbot von Bing: »Wir empfehlen, ChatGPT als Quelle der Inspiration und des Feedbacks zu verwenden – aber nicht als Quelle der Information.«
Wer die kostenlose Version von ChatGPT nutzt, gibt sein Einverständnis, dass die Daten zur Weiterentwicklung des Modells verwendet werden dürfen. Das will nicht jeder. »Alle hoffen, dass man durch solche Sprachmodelle mehr Produktivität gewinnt. Es wäre aber bitter, wenn Europa diese Vorteile nur durch das Abgeben von Datensouveränität hätte«, meint Stefan Kesselheim vom Supercomputing Centre des Forschungszentrums Jülich. Den Markt dominieren derzeit amerikanische Firmen. »Ganz unzweifelhaft haben gerade Google und OpenAi einen technologischen Vorsprung. Sie sind am weitesten darin, diese Sprachmodelle einsetzbar zu machen«, so Kesselheim.
Das hat Schattenseiten, denn während die Sprachmaschinen drauflosplaudern, sind deren Produzenten verhalten bei der Frage, welche Daten sie mit welcher Software trainieren. Ein Faktum, dass Politik und Wissenschaft in Europa umtreibt. Die europäische Antwort heißt TrustLLM: »Die Idee ist, dass wir ein öffentliches Gut schaffen, also Sprachmodelle die kommerziell genutzt werden können, so dass Europa wirtschaftliche Vorteile entstehen«, sagt Kesselheim. Für die Entwicklung stellt die EU rund 7 Millionen Euro zur Verfügung. An dem dreijährigen Projekt arbeiten Forschungseinrichtungen und Unternehmen aus Deutschland, Schweden, Island, Dänemark, Norwegen und den Niederlanden.
TrustLLM soll in jeder Hinsicht besser sein als die Konkurrenz: zuverlässiger, offener, ethisch korrekt und nicht zuletzt sparsamer beim Energieverbrauch. »Es geht darum, Alternativen zu schaffen, die besser zu europäischen Werten passen«, sagt Kesselheim und nennt als Beispiel die Sprachenvielfalt in Europa. »Das Modell soll auch für Sprachen funktionieren, die nicht viele Menschen sprechen, zum Beispiel isländisch.« Das »Trust« im Projektnamen ist Programm: »Die Nutzer sollen dem Produkt und dem Produktionsprozess vertrauen«, sagt Kesselheim. So wenig Black Box wie möglich ist das Ziel und die Möglichkeit einer Opt-out-Funktion: »Das heißt, dass Datensätze nicht verwendet werden, bei denen der Besitzer verbietet, sie für das Trainieren eines Modells zu nutzen.« Auf der technologischen Seite wird es darum gehen, der Maschine »Halluzinationen«, also faktische Fehler, abzutrainieren, die das Modell als die Wahrheit verkauft.

KI-Anwendungen brauchen viel Rechen-Power. Der Jülicher Superrechner JUWELS bietet mit seinem Booster-Modul Deutschlands stärkste Plattform für KI. Bild: Forschungszentrum Jülich
Das Herzstück des Trainingszentrums, die »Maschinenhalle«, entsteht derzeit in Jülich. »Wir bauen gerade Europas größten Rechner, vielleicht sogar den weltweit größten KI-Rechner auf«, so Kesselheim. Der Jülicher Supercomputer JUPITER soll als erster Superrechner in Europa die Marke einer Trillion Rechenoperationen pro Sekunde brechen und damit Durchbrüche beim Einsatz von KI ermöglichen.
Konkret sind das rund 6.000 miteinander verschaltete, extrem leistungsfähige Einzelrechner. Sie haben eine Rechenkapazität, die etwa der von zehn Millionen moderner Notebooks entspricht. Und dafür brauchen sie sehr viel Strom: »Das einmalige Trainieren der Sprachmaschine würde einen siebenstelligen Betrag kosten«, schätzt Kesselheim.
Soft- und Hardware werden daher auf Effizienz getrimmt, denn je schneller die Trainingszeit um ist, desto weniger zeigt der Stromzähler am Ende an. Leicht ist das nicht, räumt Kesselheim ein: »Gerade auf so großen Maschinen ist es eine Herausforderung, sie so zum Laufen zu bringen, dass sie schnell und konkurrenzfähig sind.«
Für den Anfang wird sich TrustLLM auf die germanische Sprachfamilie konzentrieren. Neben englisch und deutsch gehört dazu beispielsweise schwedisch und dänisch oder isländisch. Das Projekt ist aber offen angelegt, so dass andere Forscher Sprachmodelle für weitere europäische Sprachen übernehmen und weiterentwickeln können.
Der erste europäische Supercomputer der Exascale-Klasse
»Mit JUPITER bekommen wir den vielleicht stärksten KI-Supercomputer der Welt!«
Mit JUPITER geht am Forschungszentrum Jülich im nächsten Jahr der erste europäische Supercomputer der Exascale-Klasse an den Start. Auf der weltweit größten Supercomputing-Konferenz, der SC23, die vom 12. bis zum 17. November im US-amerikanischen Denver stattfindet, wurden nun nähere Informationen zur Ausstattung bekanntgegeben. Im Interview erklärt Prof. Dr. Dr. Thomas Lippert, Direktor des Jülich Supercomputing Centre, welche Hardware bei JUPITER zum Einsatz kommen wird.
Der Jülicher Exascalerechner soll als erster Superrechner in Europa die Marke von einer Trillion Rechenoperationen pro Sekunde brechen und damit wissenschaftliche Simulationen auf eine neue Stufe heben sowie Durchbrüche beim Einsatz künstlicher Intelligenz ermöglichen.

Abb.: Prof. Dr. Dr. Thomas Lippert, Direktor des Jülich Supercomputing Centre am Forschungszentrum Jülich (Copyright: Sascha Kreklau)
Prof. Dr. Dr. Thomas Lippert, was ist das Besondere an der Hardware, mit der JUPITER 2024 die Exascale-Grenze knacken will?
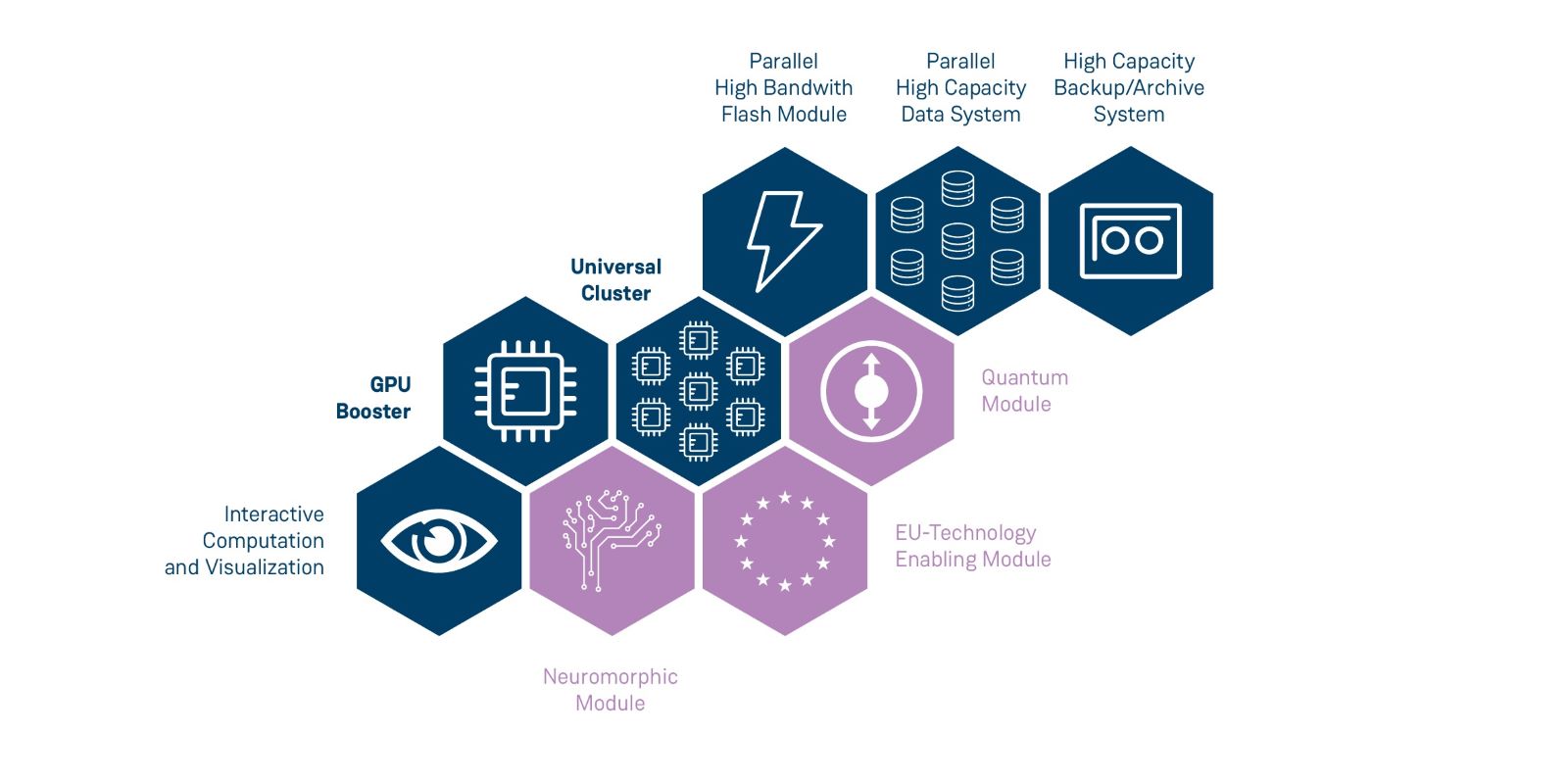
JUPITER ist ein dynamischer modularer Supercomputer, der aus zwei Teilen besteht: ein hochskalierbares Booster-Modul für besonders rechenintensive Probleme, das massiv durch Grafikprozessoren unterstützt wird, und ein Cluster-Modul, das sich sehr universell für alle möglichen Aufgabenarten einsetzen lässt, speziell auch für komplexe, datenintensive Tasks. Beide Module können getrennt oder zusammen wissenschaftliche Probleme lösen, je nach Bedarf.
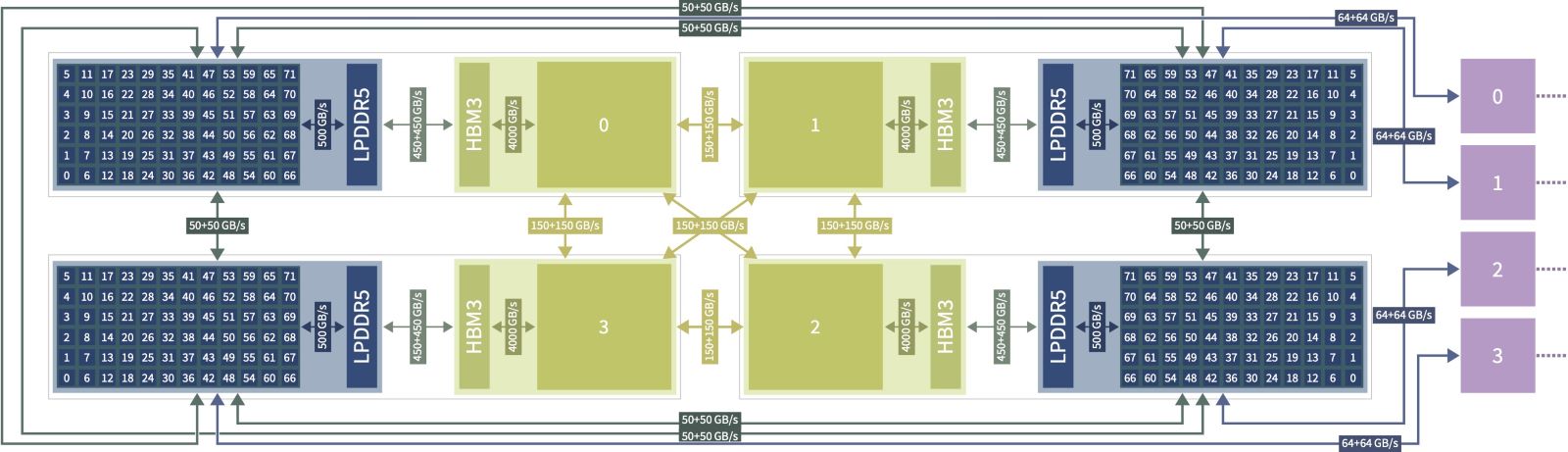
Wie gerade auf der SC23 bekannt gegeben wurde, besitzt das Booster-Modul rund 24.000 GH200-Grafikprozessoren von NVIDIA. Im sogenannten Linpack-Benchmark, der meist als Referenz genannt wird, soll JUPITER damit eine Rechenleistung von etwas mehr als einem Exaflops erreichen und darüber hinaus eine herausragende KI-Rechenleistung zur Verfügung stellen.
Für geeignete KI-Anwendungen haben wir mit über 90 Exaflops bei 8 Bit künftig den vielleicht schnellsten KI-Supercomputer der Welt!
Alle Rechenknoten von JUPITER sind mit einem Hochleistungs-Netzwerk verbunden; hier setzen wir die neueste NVIDIA Mellanox InfiniBand-Technologie ein. Das Booster-Modul wird von dem französischen IT-Unternehmen Eviden, ehemals ATOS, geliefert. Das Cluster-Modul ist mit neuen europäischen ARM-CPUs von SiPearl ausgestattet und wird von den deutschen Experten für High Performance Computing, kurz HPC, von der Firma ParTec geliefert. ParTec ist auch für den dynamischen modularen Betrieb des Systems verantwortlich. Sowohl bei der verwendeten Hardware als auch bei vielen Softwarekomponenten werden bei JUPITER Technologien Made in Europe verwendet, das ist schon etwas Besonderes!
Wie wichtig ist für einen Superrechner wie JUPITER die Wahl der Prozessoren? Bei Büro-PCs spielt der Prozessortyp ja mittlerweile oft nur noch eine untergeordnete Rolle…
Im High Performance Computing ist die Wahl der Prozessoren alles entscheidend. Dieser Aspekt war eines der Hauptkriterien bei der Auftragsvergabe bei JUPITER durch die von EuroHPC JU ausgewählten Experten. Eine wichtige Rolle spielen dabei die Grafikprozessoren, GPUs. Bei bestimmten Aufgaben sind sie universellen Prozessoren, CPUs, um fast eine Größenordnung überlegen.
Ausschlaggebend ist hierbei die hochgradige Parallelität. Klassische CPUs sind darauf ausgelegt, komplexe Aufgaben sehr schnell hintereinander abzuarbeiten. CPUs besitzen daher typischerweise weniger, dafür aber sehr leistungsstarke Rechenkerne. GPUs verfügen stattdessen über sehr viel mehr Rechenkerne als CPUs, die für sich gesehen aber nicht ganz so leistungsstark sind.
Die neuen GH200-Grafikprozessoren von NVIDA verfügen beispielsweise über Tensor-Cores pro Chip, die sehr schnelle Berechnungen im Bereich der künstlichen Intelligenz ermöglichen. SiPearl verspricht mit ihrer Rhea-CPU dagegen eine gewaltige Memory-Datenrate von 0,5 Bytes pro Flop, fast fünfmal so viel wie bei einer GPU – und damit eine hohe Effizienz bei komplexen, datenintensiven Anwendungen.
In der Tat spielt aber auch das Netzwerk des Systems eine gewaltige Rolle, insbesondere gilt das für den dynamisch-modularen Betrieb. Das Hochleistungsnetzwerk basiert auf der neuesten Generation NVIDIA Mellanox InfiniBand NDR und nutzt eine Topologie bestehend aus mehreren Gruppen, in die sich einzelne Module des Systems abbilden lassen und bei denen dennoch eine starke Verbindung zwischen den einzelnen Gruppen besteht.
Kritische Stimmen bemängelten zuletzt, Superrechner in Deutschland und Europa seien nicht ausreichend für das Training neuronaler Netze für KI ausgelegt. Wie es um JUPITER in dieser Hinsicht bestellt?
Seit Jahren stellen wir am Jülich Supercomputing Centre schon KI-Rechenzeit für Wissenschaftlerinnen und Wissenschaftler zur Verfügung. Speziell die Installation des GPU-basierten JUWELS Booster im Jahr 2020 – zugleich Europas schnellster Supercomputer – erwies sich als bahnbrechend für die Nutzung von KI-Modellen. Das System war von uns schon sehr früh für KI-Anwendungen ausgelegt. Der JUWELS Booster verfügt über mehr als 900 Rechenknoten, von denen jeder einzelne 4 Grafikprozessoren und eine sehr hohe Netzwerkbandbreite bereitstellt; die tiefen neuronalen Netze passen einfach perfekt zu diesen GPUs!
Europa hat sowohl die notwendige Rechenleistung als auch Kompetenz in der Softwareentwicklung, um bei KI innovativ zu sein.
Unsere Nutzer trainieren zunehmend KI-Modelle auf dem System. Bei den großen Foundation-Modellen wird immer wieder das gesamte System auf einmal ausgelastet. Auch an anderen europäischen Zentren, mit denen wir über EuroHPC-JU verbunden sind, sind nach 2021 vermehrt Superrechner mit GPU-Beschleunigern in Betrieb genommen worden. JUPITER bildet nun einen weiteren Meilenstein. Das heißt, Europa hat sowohl die notwendige Rechenleistung als auch Kompetenz in der Softwareentwicklung, um bei KI innovativ zu sein. An dieser Stelle möchten wir auch die vor kurzem veröffentlichte KI-Strategie des Bundesministeriums für Bildung und Forschung erwähnen.
Für welche Anwendungen ist JUPITER noch ausgelegt?
Die Unterstützung von wissenschaftlichen HPC-Anwendungen stand von Anfang an im Fokus. Wir orientierten uns für JUPITER an unserer aktuellen Nutzerschaft und den zu erwarteten Anwendungen in der Zukunft. Neben KI-Anwendungen gibt es ein großes Feld von HPC-getriebenen Wissenschaften, die wir mit JUPITER unterstützen. Zum einen sind dies hochparallele Anwendungen, die ebenfalls vom GPU-basierten Booster-Modul profitieren – zum Beispiel Klimasimulationen, Strömungsmechanik-Simulationen, oder Molekulardynamik-Simulationen. Wir haben eine heterogene Nutzerschaft mit den besten Anwendungen aus vielen wissenschaftlichen Domänen. Das Cluster-Modul von JUPITER fokussiert sich auf Anwendungen, die höhere Anforderungen an serielle Leistung und Speicher-Bandbreite haben, zum Beispiel irreguläre Zugriffsmuster von elementarphysikalischen Simulationen. Dank der modularen Architektur von JUPITER können Anwendungen auch beide Komponenten gleichzeitig einsetzen und so die Rechenressourcen effizient einsetzen. Eine besondere Art solcher heterogenen Anwendungen verbindet klassische HPC-Simulationen mit KI-Methoden, zur Erhöhung von Genauigkeit und Effizienz. Mit JUPITER sind wir ideal dafür aufgestellt.
Technical Overview: A Deep Dive Into JUPITERs Building Blocks
Dieser technische Überblicksartikel liefert Hintergrundinformationen und technische Details zu den gewählten Architekturen der verschiedenen Komponenten von JUPITER. >>> mehr (auf Englisch)