

In allen Unternehmen mit mehr oder weniger komplexen Geschäftsprozessen ist die heute anfallende Datenmenge enorm. Es hat sich mittlerweile herumgesprochen, dass eine gezielte Analyse dieser Daten unterschiedliche positive Effekte für ein Unternehmen bringt. Der Bedarf an Data-Science-Know-how ist deshalb groß wie nie, und der Kampf um diese Ressourcen zwischen den Abteilungen ist bereits in vollem Gange.
Ausschlaggebend für eine sinnvolle Analyse von Daten sind diejenigen Personen, die einerseits Zugriff auf die vielen, unterschiedlichen Datenquellen haben und andererseits über ein tiefes Verständnis verfügen, was man aus diesen Informationen herauslesen und mit ihnen erzielen kann. Es ist kein Geheimnis mehr, dass ein Unternehmen mit einem eigenen, professionellen Data-Science-Team im Besitz eines entscheidenden Wettbewerbsvorteils ist.
So hoch das Thema Data Science unter Business-und IT-Führungskräften gehandelt wird, so ernüchternd ist die Situation am Arbeitsmarkt, wenn es darum geht, diese Experten anzuheuern. Aus dieser Not heraus haben sich in den letzten Jahren in Unternehmen einzelne Mitarbeiter in das große Feld der Data Science hineingearbeitet. Doch der oft intrinsisch motivierte Datenbastler und Frickler, der die Nische »Analyse« in seinem Unternehmen mit sehr hohem unternehmensinternen Daten- und Prozesswissen besetzt, kommt mittlerweile an seine Grenzen.
Die Professionalisierung von Data Science. Um immer komplexeren Business-Tasks, der Entwicklung neuer Produkte und Dienstleistungen und der Optimierung von Prozessen gerecht zu werden, sind Unternehmen zunehmend auf analytische Einsichten von Data-Science-Teams angewiesen, die nicht nur technisch versiert sind, sondern auch über Markt-Know-how verfügen und gleichzeitig gute Kommunikatoren sind. Als Folge erlebt der Bereich Data Science in den letzten Jahren eine zunehmende Professionalisierung und Standardisierung.
In unserem Beratungsalltag erleben wir immer häufiger, dass ein Unternehmen uns nach Unterstützung beim Aufbau eines schlagkräftigen Data-Science-Teams fragt. Bei der Umsetzung stellt sich dann bald die die Frage, ob und wie man die oben beschriebene »One-Man-Show« institutionalisiert und damit in das Netzwerk eines Unternehmens beziehungsweise dessen Organigramm einpasst. Im nächsten Schritt stellt sich die entscheidende Frage, ob man die Data-Science-Kompetenz in einem Team bündelt oder dezentral über verschiedene Abteilungen verteilt.
Die Anwendungsfälle. Welches Ziel verfolgt ein Unternehmen mit dem Aufbau eines Data-Science-Teams? Welches Data-Science-Produkt entwickelt das Team? Die Antworten auf diese Fragen sind kritisch und sollten früh geklärt werden.
Bei der Definition der Zielsetzung und des Data-Science-Produkts ist die Unterscheidung zwischen Ad-hoc-Analyse und analytischer Applikation entscheidend:
Ad-hoc-Analyse: Eine Analyse ist statisch und wird nicht produktiv genutzt beziehungsweise ist nicht in den Kontext einer Anwendung eingebunden. Ein klassisches Beispiel wäre hier eine Kundensegmentierung, die auf einem Snapshot der Kundenbasis zu einem gewissen Zeitpunkt entstanden ist. Es werden Handlungsempfehlungen abgeleitet, umgesetzt und zu einem späteren Zeitpunkt evaluiert. Dies geschieht aber nicht fortlaufend.
Analytische Applikation: Am anderen Ende des Kontinuums steht die analytische Applikation. Die Segmentierung wird genutzt, um Kunden, die auf eine Webseite kommen, zu kategorisieren und die Nutzererfahrung so zu individualisieren. Die Verarbeitung der dafür nötigen Information kann zur Laufzeit geschehen. Der Kunde einer Data-Science-Abteilung muss jedoch nicht immer der Endkunde sein; so gibt es die Möglichkeit, interaktive Applikationen für einen kleinen Kreis, beispielsweise nur im Intranet zur Verfügung zu stellen. Das kann zum Beispiel eine interaktive Visualisierung einer Szenariorechnung sein. So lässt sich für das Management direkt erkennen, wie sich gewisse Entscheidungen (simuliert) auf den Geschäftserfolg auswirken. Denkbar ist hier zum Beispiel die interaktive grafische Aufbereitung von Wechselströmen von Kunden zwischen verschiedenen Tarifen auf Basis der relativen Preisunterschiede zweiter Produkte.
Zentral oder dezentral? Je nachdem, wie man sein Data-Science-Team im Unternehmen organisieren möchte, entscheidet man sich entweder für ein Data Science Competence Center auf der anderen Seite oder für Data Scientists in den jeweiligen Fachabteilungen. Das bringt Vor- und Nachteile mit sich, wie in den Tabellen dargestellt.
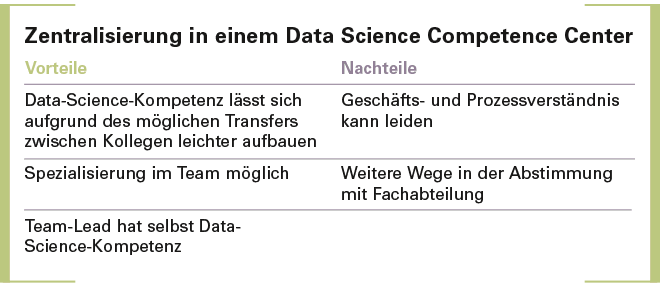
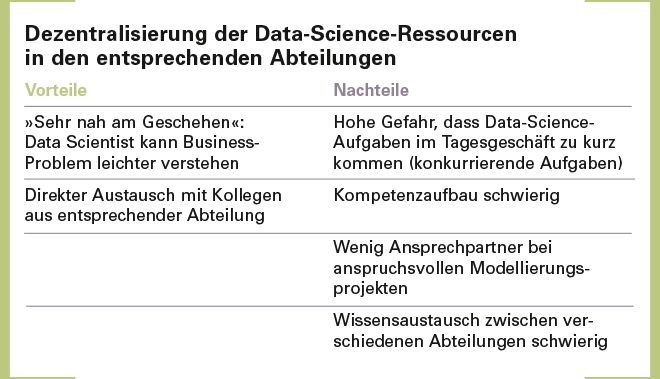
Fazit. Sobald sich das analytische Zielbild einer Organisation auf der Achse Ad-hoc Analyse vs. Data Product weiter in Richtung Data Product entwickelt, wird eine Zentralisierung in ein Data Science Competence Center notwendig.
Da ist zum einen eine verstärkte Spezialisierung, die bei der Entwicklung einer Applikation notwendig ist: Es sollten im Team neben der Kompetenz, das Geschäftsmodell zu verstehen, Daten aufzubereiten und Modelle zu entwerfen und zu implementieren, auch die Fähigkeiten der Software-Entwicklung vorhanden sein. Hierzu bedarf es spezieller Kenntnisse, nicht nur betreffend der Frontend-Sprachen, sondern unter Umständen auch in Bezug auf die technische Architektur und auf das Verständnis für einen Software-Entwicklungs-Lifecycle. Dieses umfangreiche Aufgabenportfolio und das Anforderungsprofil an entsprechende Skills lässt sich schwer von einem Mitarbeiter alleine bewältigen.
Der größte Kritikpunkt an einer zentralen Einheit ist das vermeintlich fehlende Verständnis für die Geschäftsprozesse in einer spezifischen Abteilung wie dem Marketing: »Wie kann jemand, der sonst Logistikoptimierung macht, nun plötzlich Bid-Management übernehmen?«, ist ein häufig genannter Einwand. Um dem Fachbereich einen kompetenten Ansprechpartner an die Hand zu geben, der auch als Sparringspartner dienen kann, ist wiederum eine Spezialisierung innerhalb der Data-Science-Teams nötig.
So wird nicht nur für eine kontinuierliche Weiterentwicklung der Data-Scientist-Frage Sorge getragen, sondern durch die Teamstruktur auch der für die Modellierung benötigte Freiraum erwirkt. Wir erleben sehr häufig, dass in der Praxis gute Data Scientists nicht zu ihrer eigentlichen Aufgabe kommen, sondern primär kurzfristige Analyse- und Reporting-Aufgaben erfüllen.
Wie man aus den Zeilen erkennt, ist der erfolgreiche Aufbau eines Data-Science-Teams keine leichte, aber doch sehr kritische Entscheidung für das Business. Die Entscheidung für die richtige Organisationsform, die im Idealfall das Zielbild meiner Organisation widerspiegelt, ist nur eine der relevanten Angelegenheiten. Im nächsten Schritt tauchen dann weitere Fragen auf wie: »Welche Prozesse und Methodiken und Standards bieten sich an?« oder »Wie funktioniert Projektmanagement im Kontext des ›Working with Uncertainty‹?«.
 Simon Nehls,
Simon Nehls,
Senior Consultant im
Competence Center
Data Science, b.telligent
www.btelligent.com