Zum besseren Verständnis der zunehmenden Bedeutung von Spark bei Big Data hat die Taneja Group ein großes Marktforschungsprojekt durchgeführt und rund 7.000 Teilnehmer befragt. In die weltweit angelegte Analyse wurden Führungskräfte aus Technik und Verwaltung einbezogen, die unmittelbar mit dem Thema Big Data zu tun haben. Die mit überwältigender Resonanz abgeschlossene Studie gibt Aufschluss die Erfahrungen mit und Beweggründe für die Einführung von Spark, die aktuelle Wahrnehmung, favorisierte Anbieter und die Zukunft von Spark selbst [1].
Spark ist ein fester Bestandteil von CDH und wird mit Cloudera Enterprise unterstützt. Als offener Standard für flexible In-Memory-Datenverarbeitung ermöglicht Spark Batch, Realtime und moderne Analysen auf der Apache-Hadoop-Plattform.
»Apache Spark hat sich sehr schnell zu einem der führenden Open-Source-Projekte im Bereich Big Data entwickelt«, sagt Mike Matchett, Senior Analyst und Consultant bei der Taneja Group. »Wir fanden heraus, dass über alle Branchen, Unternehmensgrößen und Reifegrade der Big-Data-Anwendungen hinweg, Spark von mehr als der Hälfte aller Befragten bereits aktiv eingesetzt wird. Und es erweist sich als äußerst wertvoll: 64 Prozent der gegenwärtigen Spark-Nutzer planen bereits eine deutliche Erweiterung in den nächsten zwölf Monaten. Die Zahl der Workloads, die Echtzeit-Datenstreaming für Analysen benötigen, nimmt zu. Hinzu kommen Anwendungen im Machine-Learning und Data-Science-Anwendungsszenarien. Vor diesem Hintergrund hat sich Spark ganz eindeutig fest etabliert.«
Die wichtigsten Ergebnisse der Taneja-Studie
Zu den wichtigsten Ergebnissen der »Apache Spark Market Research Study« zählen ein hohes Maß an Wachstum und Dynamik beim Einsatz von Spark, der über erwartete ETL-Workloads für Datenverarbeitung/ -engineering hinausgeht, sowie ein künftiger Übergang auf Cloud-Deployments. Auch andere Erkenntnisse der Studie sind bemerkenswert:
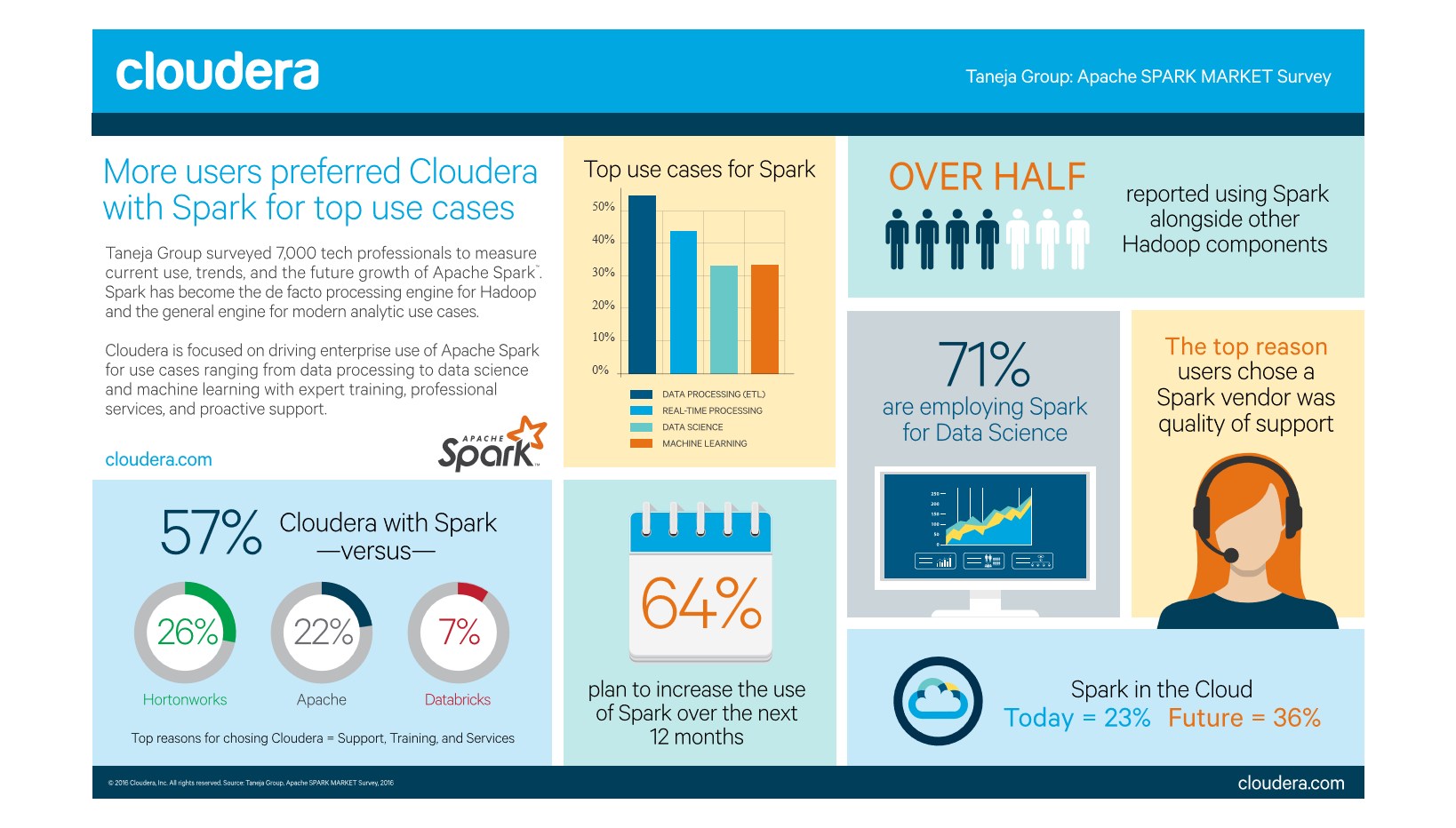
- Etwa die Hälfte aller Befragten (54 Prozent) setzt Spark bereits aktiv ein. 64 Prozent der gegenwärtigen Anwender sprechen Spark einen unschätzbaren Wert zu und wollen die Nutzung innerhalb der nächsten zwölf Monate deutlich erweitern.
- Wachsende Akzeptanz: Vier von zehn Befragten, die mit dem Big-Data-Projekt vertraut sind, wollen Spark in nächster Zeit erstmals einsetzen.
- 57 Prozent aller Befragten vertrauen bei den wichtigsten Anwendungsfällen auf Spark in der von Cloudera bereitgestellten Form – mehr als doppelt so viele, wie bei den darauf folgenden drei Apache-Hadoop-Anbietern zusammengenommen. Kunden, die vorzugsweise auf Cloudera setzen, heben als wichtigste Leistungsmerkmale das damit verbundene Modell zur Sicherheits- und Regelkonformität, die Stabilität und Leistung, die Übertragbarkeit auf die Cloud, die Einbindung eines umfangreichen Software-Paketes zur Verarbeitung, Abfrage und Analyse von Daten sowie Dienste zum Machine Learning hervor.
- Neben den erwarteten ETL-Workloads aus den Bereichen Datenverarbeitung/ -engineering – die momentan über 55 Prozent der benannten Spark-Einsätze darstellen – geht es bei den aktivsten Spark-Initiativen vor allem um die Verarbeitung von Realtime-Streams, um Data-Science-Forschung und um den aufkommenden Spark-Einsatz für Machine Learning. All dies sind Bereiche, in die Cloudera weiter investiert.
- Unverändert stellen Lücken in der Big-Data-Kompetenz und fehlende Möglichkeiten zur Teilnahme an entsprechenden Schulungen unterschiedlicher Art (Online, individuelles Training, Konferenzen oder Messen) die größten Hürden und Herausforderungen des Spark-Einsatzes dar. Über professionelle Dienstleistungen, hochwertige Beratung und eine große Bandbreite an Partnern bildet Cloudera mehr Apache Spark-Profis aus als jeder andere Hadoop-Anbieter.
»Bei Cloudera konzentrieren wir uns auf die Führung im Unternehmenssektor und bieten vor allem die Sicherheit, Datensteuerung und Compliance, die unsere Kunden benötigen”, sagt Mike Olson, Gründer und Chief Strategy Officer von Cloudera. »Die Studienergebnisse unterstreichen, wie wichtig es einerseits ist ›Enterprise ready‹ zu sein und andererseits auch gut vorbereitet auf zukünftige Einsatzgebiete von Spark. Genau das ist der Grund, wieso eine überwältigende Zahl an Kunden Spark lieber von Cloudera als von anderen kommerziellen Anbietern bezieht.«
Die Studie beschreibt auch genau die hervorgehobene Rolle der Public Cloud in Verbindung mit Spark: »Obwohl On-Premise-Installationen von Spark heute überwiegen, besteht ein großes Interesse daran, viele davon in die Cloud zu übertragen«, stellt Mike Matchett von der Taneja Group fest. »Insgesamt werden Spark-Deployments in der Public-/ Private-Cloud (IaaS oder PaaS) zukünftig deutlich zunehmen, von heute 23 Prozent auf 36 Prozent.«
[1] Die Studie steht hier nach Registrierung kostenlos zum Download bereit. https://tanejagroup.com/profiles-reports/request/apache-spark-market-survey-cloudera-sponsored-research#.WCvO6IWcEb-
Jede 20. Android-App verwundbar: Sicherheitslücke in Apache Cordova
Verknüpfung von BI und Big Data hebt Datenanalysen auf neues Niveau
Hadoop erreicht strategischen Status, aber die Umsetzung stockt
Business Intelligence – Aus Daten entscheidungsrelevante Informationen gewinnen
Internet of Things – Smarte Wertschöpfung mit dem Internet der Dinge
Hadoop und Data Vault – Ein evolutionärer Ansatz für Big Data
HTTP/2: Vier bedeutsame Schwachstellen des neuen World-Wide-Web-Protokolls