
Illustration Absmeier foto freepik
Edge Computing ist auf dem Weg, für ein neues Internet zu sorgen. In einer Zeit, in der Konsumenten und Unternehmen eine möglichst kurze Zeitspanne zwischen einem Problem und einer Antwort darauf verlangen, bietet Edge Computing eine besondere Möglichkeit: Sie verkürzt die Zeitspanne, die für die Bereitstellung dieser Informationen benötigt wird. Edge Computing sorgt für diesen Schritt, indem es die Latenzzeit verringert, Daten auch bei unzureichender Bandbreite verarbeitet, die Kosten senkt und die Datenhoheit sowie die Compliance gewährleistet.
Das zentralisierte Cloud Computing wird zwar weiter bestehen, aber die radikal andere Art und Weise, wie man jetzt Daten am Rande des Netzwerks erstellen und verarbeiten kann, wird neue Märkte schaffen – und tut dies auch bereits. Für das Jahr 2024 wird aktuell erwartet, dass der globale Markt für Edge Computing einen Wert von über 9 Milliarden Dollar erreichen wird – mit einer durchschnittlichen jährlichen Wachstumsrate von 30 Prozent.
Angesichts dieser Situation lautet die zentrale Frage jetzt: Welche Betriebsmodelle und Technologien sind wirklich in der Lage, dieses Potenzial in der Praxis effektiv zu erschließen?
Sascha Haase, VP Edge beim Hamburger Kubernetes-Experten Kubermatic, geht dieser Frage nach:
»Als neuer Anwendungsbereich ist Edge Computing derzeit oft noch ein unbeschriebenes Blatt, für das sich erst noch bewährte Verfahren herausbilden müssen. Auch ohne feststehende Standards in diesem Bereich beginnen viele Unternehmen bereits, sich für ihre Anforderungen beim Edge Computing der Technologie von Kubernetes zuzuwenden.
Kubernetes verwirklicht den Ansatz von Edge Computing
Kubernetes hat die Unternehmens-IT bereits im Sturm erobert, wobei laut der jüngsten Umfrage der Cloud Native Computing Foundation (CNCF) bereits 86 Prozent der Unternehmen Kubernetes verwenden. Kubernetes wurde zwar für die Cloud entwickelt, aber die Vorteile, die es bietet, erstrecken sich auch auf den schnell wachsenden Markt für Edge Computing.
Mit Hard- und Software, die über Hunderte oder sogar Tausende von Standorten verteilt sind, ist eine besonders durchdachte technische Lösung erforderlich: Nur so lassen sich diese verteilten Systeme, die durch Technologien von Cloud Native verwaltet werden, angemessen standardisieren und automatisieren.
Wenn Unternehmen jedoch wirklich Kubernetes für die Verwaltung ihrer Installationen von Edge Computing verwenden möchten, müssen sie die anderen Herausforderungen, die der Edge-Bereich mit sich bringt, sorgfältig berücksichtigen.
Das größte Problem besteht in der Beschränkung der Ressourcen. Kubernetes wurde in der Cloud mit ihren nahezu unbegrenzten Skalierungsmöglichkeiten entwickelt. Im Gegensatz dazu verfügt Edge Computing in der Regel über eine sehr begrenzte Anzahl von Ressourcen. Die tatsächlichen Beschränkungen können sogar erheblich variieren, von einigen wenigen Servern bis hin zu ein paar hundert Megabyte an Speicher, wenn man sich vom regionalen Edge zum Device Edge bewegt. Allen gemeinsam ist jedoch die Einschränkung, dass jeder noch so kleine Overhead die Ausführung der eigentlichen Anwendungen beeinträchtigt.
Vor diesem Hintergrund stellt sich nun die Frage: Wie kann man die Auswirkungen von Kubernetes reduzieren, um mehr Platz für die Anwendungen der Kunden zu organisieren?
Der kleinste Cluster von Kubernetes
Ein Kubernetes-Cluster besteht aus der Steuerungsebene und den eingesetzten Knoten. Um diesen Fußabdruck zu verkleinern, haben einige Projekte versucht, eher unwichtige Elemente aus Kubernetes zu entfernen, um eine abgespeckte Version zu erstellen.
Dadurch entsteht jedoch ein Kubernetes-Kern, der unabhängig vom Rest des Kubernetes-Stacks gewartet und verwaltet werden muss. Anstatt zu versuchen, einzelne Elemente zu entfernen, kann man auch die Architektur der Cluster neu gestalten und dabei prinzipiell berücksichtigen, wie Edge Computing aufgebaut ist.
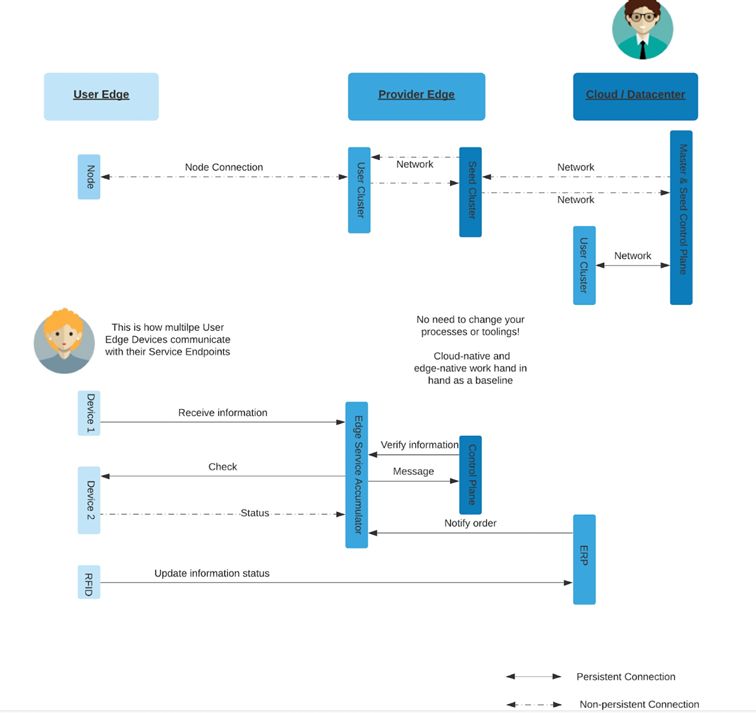
Edge Computing besteht aus keinem bestimmten Ort oder Gerätetyp, sondern ist eher als ein Kontinuum von Standorten zu begreifen, die vom zentralisierten Cloud Computing entfernt sind. Je weiter man sich von der eigentlichen Cloud entfernt, desto eingeschränkter funktionieren in der Regel die Geräte und Bandbreiten.
Jede Ebene des Edge Computing ist jedoch in der Regel mit mindestens einer der darüber liegenden Ebenen verbunden und wird in gewissem Maße von dieser gesteuert. Der Edge-Bereich ist der Ort, an dem die Arbeitslast ausgeführt wird, aber er ist immer noch mit dem zentralisierten Computing für Funktionen auf höherer Ebene verbunden.
Man kann sich Kubernetes als zwei unabhängige Teile vorstellen: als einen zentralen Teil für die Steuerung und als einen verteilten Teil für die Datenverarbeitung. Die Arbeitsknoten führen die Anwendungen aus, während die Steuerungsebene lediglich die Installation und Wartung der im Cluster ausgeführten Arbeitslasten übernimmt.
Damit ein Workload einfach nur funktioniert, wird die Steuerungsebene eigentlich nicht benötigt, da sie nur das Management der Lebenszyklen übernimmt. Wenn der Arbeitsknoten die Verbindung zur Steuerungsebene verliert, können die Workloads jedoch weiterhin funktionieren und ausgeführt werden, sie können aber nicht mehr aktualisiert werden.
In diesem Sinne kann man sich die funktionale Einheit eines Kubernetes-Clusters als die Arbeitsknoten mit einem Kubelet vorstellen. Die zentralisierte Verwaltung der Steuerungsebene ist nicht die ganze Zeit über erforderlich, damit die Arbeitslast funktioniert.
Mit diesem neuen Konzept dessen, was ein Kubernetes-Cluster eigentlich darstellt, kann man anfangen zu überdenken, wie Kubernetes-Cluster für Umgebungen mit begrenzten Ressourcen aufzubauen sind. Die Arbeitsknoten können auf bestimmten Geräten ausgeführt werden, während die Steuerungsebene an einem zentraleren Ort mit zusätzlichen Ressourcen ausgeführt wird, sei es in einem Rechenzentrum vor Ort oder sogar in der öffentlichen Cloud. Auf diese Weise können Operations-Teams Kubernetes auf Edge Computing ausführen, ohne Änderungen vornehmen oder einen anderen Technologie-Stack aufrechterhalten zu müssen – und das bei minimalem Overhead.
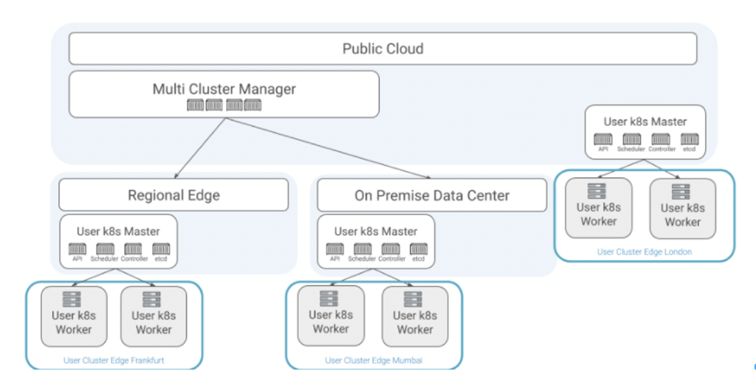
Chaos im Cluster-Management
Der Markt für Edge Computing in einem Umfang von mehreren Milliarden Dollar wird aus Billionen von Geräten bestehen, auf denen Millionen von Clustern laufen. Daher stellt sich die Frage, wie diese verwaltet werden können und wie die Steuerungsebene und die Arbeitsknoten synchron gehalten werden können, auch wenn sie an verschiedenen Standorten laufen.
Kubermatic hat KKP (Kubermatic Kubernetes Plattform) auf Open Source mit Blick auf diesen Anwendungsfall entwickelt. Ihre Kubernetes-in-Kubernetes-Architektur trennt bereits die Kontrollebene von den Arbeitsknoten und verwaltet sie unabhängig. Die Steuerungsebene wird als eine Reihe von Containern in einem anderen Cluster ausgeführt, der in einer weniger ressourcen-beschränkten Umgebung betrieben werden kann, während die Arbeitsknoten nur ein Kubelet ausführen müssen, wodurch der Fußabdruck des Kubernetes-Clusters am Rande radikal reduziert wird. Darüber hinaus automatisiert die Kubermatic Kubernetes Platform das Management des Cluster-Lebenszyklus, was besonders für Geschäfts- und Betriebsmodelle von Edge Computing wichtig ist.