

foto freepik
Die Datenflut in Unternehmen steigt und steigt. Damit wird es immer noch schwieriger, wirklich schnell alles Wissen aus den Daten herauszuholen. Das Zusammenführen der Daten aus den verschiedenen Quellen gilt als Killer-App für wirklich datenbasierte Prozesse und Entscheidungen in Unternehmen. Helge Scheil ist bei Fivetran für das Engineering und Software-Development zuständig. Er erklärt, worauf es beim automatisierten Data Movement und bei der Implementierung von Data Pipelines ankommt.

Helge Scheil, Engineering und Software-Development, Fivetran
Herr Scheil, wie steht es bei deutschen Unternehmen um den Zugang zu Daten?
Wir erleben eine Menge unterschiedlicher Projekte. Aber es geht immer darum, Daten zusammenzuführen. Egal ob es sich um Datenzentralisierungs- oder Datendezentralisierungsprojekte handelt – oder um Data-Mesh-Initiativen, Federated Data Stores oder anderes. Das alles brauchen Unternehmen für alltägliche Dinge wie Business Intelligence und Datenanalyse aber auch für operative Prozesse. Und natürlich sehen wir den Hype um generative AI. Hier gilt »Garbage in, Garbage out«. Das heißt, eine KI kann nur so gut sein, wie man die Daten qualitativ zentralisieren kann, um die AI Bots, das Machine Learning und so weiter zu füttern. Und da gibt es vor allem im Enterprise-Bereich eine große Nachfrage. Hier geht es ganz konkret um ChatGPT, Open AI und Co.
In Unternehmen gibt es tausende Excel-Listen, Systeme für CRM und ERP und auch sonst überall Daten: Mit welchen Schwierigkeiten haben Unternehmen heute zu kämpfen?
Eines der Hauptthemen ist, wie schnell man Informationen den eigentlichen Nutzern zur Verfügung stellen kann. Wir haben uns hier gerade mit einem sehr großen Unternehmen getroffen. Wenn es zum Beispiel der Marketing-Abteilung oder dem Vertrieb ein neues Datenelement zur Verfügung stellen will, kann das bis zu sechs Monate dauern. Ein halbes Jahr, bis die bestehenden Datenpipelines und Datenströme angepasst sind, bis Data Governance gewährleistet ist und Release-Mechanismen durchgeführt werden können. Das ist sicherlich ein Extrembeispiel. Aber hier gibt es eben einen mehrstufigen Prozess, der die IT-Abteilung und Programmierer sowie Data Engineers braucht, dazu kommen noch Data-Governance-Verantwortliche und eine Managementebene.
Dabei wäre ein Ansatz ideal, der via Self Service den eigentlichen Nutzern erlaubt, ganz einfach ohne IT-Spezialwissen auswählen zu können, welche Tabelle oder welche Spalten sie noch für ihre Arbeit benötigen. Das heßt, die Fachabteilung sollte ohne Data Engineers den Zugang und die Verbindung von Datenquellen herstellen können. Ein Self Service sollte sehr simpel angelegt sein und man sollte durch Point und Klick die Daten ganz einfach schnell zum Fließen bringen. Natürlich gibt es auch für die Implementierung einer solchen automatisierten Lösung Kontrollprozesse und bezüglich Datensicherheit muss man sorgfältig vorgehen. Aber sechs Monate sollten sich auf wenige Tage reduzieren lassen.
Zudem mangelt es Unternehmen immer noch an Data Engineers und Data Scientists, die tatsächlich »in den Daten« arbeiten können und somit den Ansatz unterstützen können. Das heißt der Fachkräftemangel ist ein Problem. Und es gibt ja noch weitere Herausforderungen, die mit dem Mangel an Ressourcen zu tun haben. Denn Data Pipelines muss man ja nicht nur erstellen, sondern auch operativ instand halten – nicht nur von 9 bis 17 Uhr, sondern auch um zwei Uhr morgens am Samstag. Dazu kommt, dass Unternehmen bis zu 300 verschiedene Datenquellen haben können. Das heißt, man braucht viele Spezialisten pro Unternehmen, die die Data Pipelines implementieren, konfigurieren und betreiben. Wenn hingegen Konfiguration, Betrieb, Instandhaltung und Weiterentwicklung ausgelagert sind, kann sich das Team auf die Analyse und Weiterverarbeitung der Daten fokussieren und muss sich nicht um Data Movement kümmern.
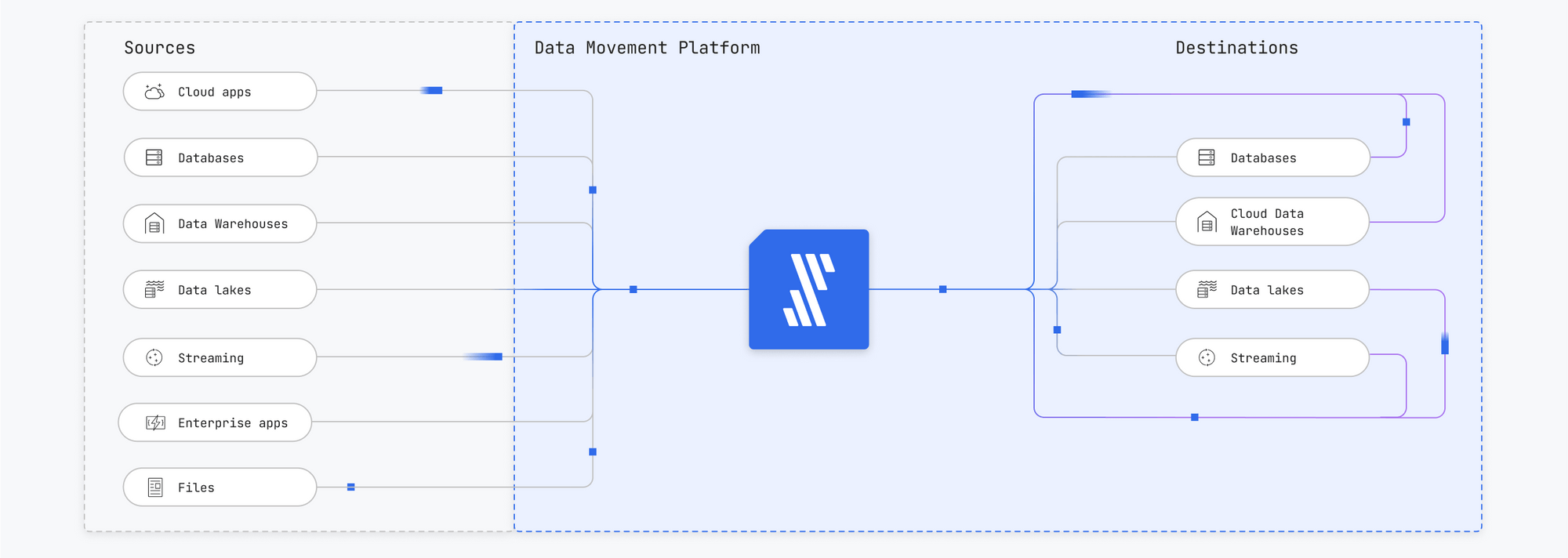
Quelle: Fivetran
Gibt es noch andere Herausforderungen für Unternehmen, zum Beispiel Data Governance, Data Quality oder Data Trust?
Fragen wie »Wo gehen die Daten hin? Wo sind sie hergekommen? Wer hat sie angefasst? Wer hat sie geändert?« sind elementar wichtig. Alle wollen alles über Daten wissen. Und die Daten dürfen Deutschland meist nicht verlassen. Das heißt, Unternehmen haben eine Menge Aufgaben zu lösen. Themen wie Stabilität, Infrastrukturqualität, Sicherheit, Datentransport, Verlässlichkeit der Data Pipelines, Datenintegrität sind entscheidend. Und: Das alles gilt für jede einzelne Datenquelle, muss also entsprechend multipliziert werden mit der Anzahl der Konnektoren. Eine weitere Herausforderung ist es, dass es für viele Prozesse und Geschäftsmodelle unerlässlich ist, den Datenfluss nicht zu unterbrechen. Bei den Geschäftsmodellen von Facebook, Linkedin, Google und Co geht es um Daten und darum, wie Unternehmen diese nutzen können. Wer diese Daten am schnellsten und besten nutzen kann, hat einen Vorteil. Wir bleiben bei den Pipelines zu diesen Systemen am Ball und bringen zum Beispiel die Daten-Pipeline wieder zum Laufen, wenn etwa einer der großen Anbieter eine API ändert. Wir tun das aktiv und kollaborativ mit allen Beteiligten. Generell ist unsere Verlässlichkeit sehr hoch. Wir messen das sekundengenau, wenn etwa eine Pipeline nicht aktualisiert wurde. Wenn zum Beispiel aufgrund eines Source-Fehlers der Timer angeht, dann schauen wir, dass wir das nach Sekunden wieder zum Laufen bekommen, je nach Souveränität oder Priorität. Unsere Up-Time liegt bei 99,95 Prozent.
Wie steht es dabei um Datenschutz und Compliance?
Wir haben diverse Compliance-Zertifikate, wie etwa ZOK2, Regional Data Processing Agreement, GDP und andere – auch die verschiedenen Versionen in verschiedenen Ländern. Und darüber hinaus garantieren wir, dass die Daten Deutschland nicht verlassen. Wir haben Ressourcen bei AWS, GCP oder Azure in Frankfurt. In unserem Produkt kann man auswählen, wo die Daten verarbeitet werden sollen. Man kann festlegen, über welche Netzwerkkanäle die Daten hin- und hergeschoben werden. Stichwort AWS Private Link: Die Daten verlassen so das AWS Ecosystem nicht: Man weiß, wo das Zielsystem ist, wo die Quelle ist und man kann relativ einfach sicherstellen, dass die Daten nie AWS verlassen. Somit können Unternehmen, die ganz besonders an Data Privacy sowie Datensicherheit und Datenschutz interessiert sind, alles in ihrem eigenen Rechenzentrum oder ihrem eigenen Cloud Account als Virtual Private Clouds laufen lassen. Zudem geht es auch hier um die Ressourcenfrage. Denn selbst mit beschränkten Ressourcen muss man diese Themen abhaken. Wir haben eigene Abteilungen dafür und können garantieren, dass Vulnerability Management, Application Security, Data Tracing etc. tatsächlich sichergestellt wird.
Cloud oder nicht Cloud? Ist das noch eine Frage?
Ganz Europa ist noch sehr On-Premises-lastig im Vergleich zu den USA. Aber die Cloud-Nutzung steigt und bringt neue Herausforderungen, etwa im Bereich Security. Somit sprechen wir oft über Hybrid-Ansätze. Wir bieten auch reine On-Premises-Lösungen. Das war ein Grund, warum wir das Unternehmen HVR übernommen haben. So haben wir eine Technologie, die wir jetzt zum Beispiel bei der Lufthansa einsetzen, aber auch bei vielen anderen Großkunden wie Versicherungsunternehmen oder Finanzdienstleister. Das hat vor allem mit dem Thema Sicherheit zu tun. Es geht aber auch um die Größe der Datenvolumina. Andererseits ist einer der vielen Pluspunkte einer Cloud-Lösung, dass man diese nicht selbst betreiben muss. Also bieten wir Hybrid-Lösungen an. Das heißt, aus Datensicherheit- oder Geschwindigkeitsgründen machen wir Agent-based Change Data Capture und lassen die Daten intern im Datenrechenzentrum oder On-Premises, bekommen aber nur die Metadaten.
Wie funktioniert eine solche Hybrid-Lösung?
Wir wissen aus unserem System, wann der Replication-Job und die Data Pipeline gelaufen ist. Wir wissen, wie lange es gedauert hat. Wir wissen, wer das angestoßen hat und noch ein paar andere Dinge. Aber wir sehen die Daten weder über das Netzwerk noch über den Cloud-Provider. Wir sehen, dass die Daten On-Premises gehalten werden. Metadaten dagegen sind weniger kritisch und können verarbeitet werden. Und wir bieten natürlich eine Lösung, wenn man zum Beispiel mit cloudbasierten Services wie Salesforce oder Snowflake arbeitet. Hier haben wir ein Äquivalent von On-Premises, denn wir können über PrivateLink garantieren, dass sowohl datenseitig, quellenseitig als auch zielseitig alles bei AWS sitzt. Fivetran unterstützt somit sowohl On-Premises als auch komplette Managed Services sowie entsprechende Hybrid-Ansätze.
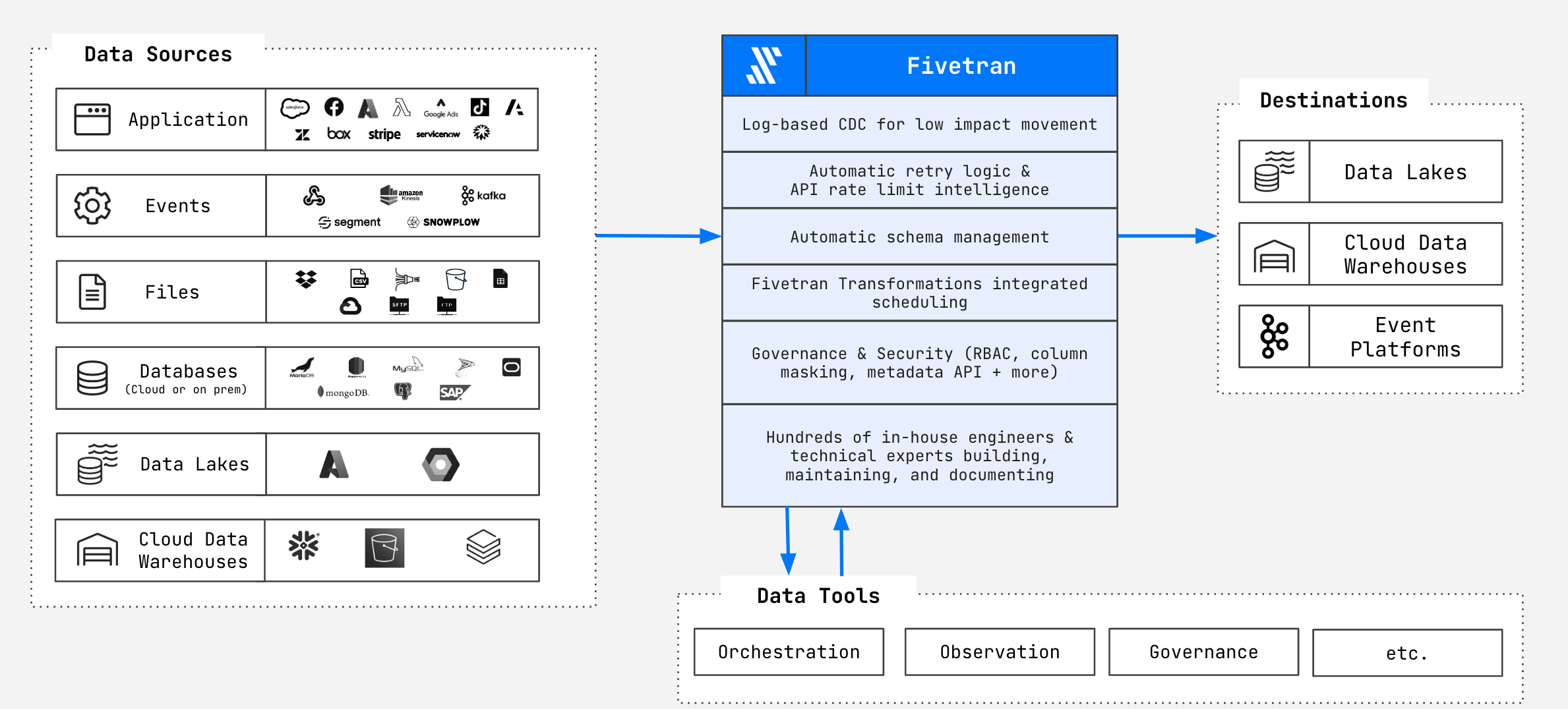
Quelle: Fivetran
Noch mehr Daten: Smart Home, Smart Cities, Autonomes Fahren, IoT etc. Wie sieht die Zukunft aus?
Vor allem werden wir über große Datenvolumina, Data Latency und Throughput sprechen und darüber, wie schnell man an die Daten kommt. Das ist eine technische Herausforderung, die wir praktisch gelöst haben – aber immer nur temporär. Denn das Volumen erhöht sich beständig. Alles wird noch vernetzter und die Anzahl der Quellen steigt stetig. Und dazu kommt die Herausforderung Realtime. Zum Beispiel haben wir momentan ein Riesenprojekt, das auf viele Datenbank-Konnektoren und Data Pipelines zielt und dabei mehrere Terabyte pro Stunde verarbeitet werden müssen.
Sehr wichtig ist auch das Thema Data Lake. Die technische Komplexität, wie, was, wann, wo genau zum Beispiel das Iceberg-Format auf S3 läuft, ist enorm. Fragen bezüglich Data Catalog und unstrukturierten Daten oder weitere Formate wie Delta Lake von Databricks oder Umgebungen wie Azure Data Lake brauchen entsprechendes Know-how und Erfahrung. Wir sind sehr, sehr intensiv im Data-Lake-Bereich unterwegs. Zum einem aus Volumen- und Kostengründen, aber auch weil wir nicht zu selektiv bei den Datenquellen sein wollen. Aber nur weil man die Daten als Rohdaten, in Tabellenformaten oder in einem anderen Format hat, heißt das noch nicht, dass man sie auswerten kann. Die Transformation, die wir auf der Destination machen, spielt die entscheidende Rolle.
Beim IoT gibt es dann auch wiederum Spezialanbieter, die eine Destination entsprechend verarbeiten und als Transaktionssystem behandeln und das dann aber weiter für Datenanalyse oder operative Zwecke weiterverarbeiten möchten. Beispielsweise nutzt die Lufthansa unsere Software, um ihre Flugplanung vorzunehmen – nicht nur für sich selbst, sondern auch als Dienstleister für andere Fluglinien. Sie nutzt Fivetran um Logistikdaten, Personaldaten, Personalverfügbarkeitsdaten, Board-Personal, Beladung mit Essen, Reinigungsmittel und vielen andere Informationen so weit zusammenzuführen, dass man letztendlich vorhersehen oder planen kann, wann der Flug genau starten kann. Geschwindigkeit und Datenvolumen aus den verschiedenen Systemen spielen eine Riesenrolle für uns.
Auf was kommt es bei einer Lösung für die Automation von Datenbewegungen an?
Reliability. Das ist für uns das höchste Gut ein echtes USP. Wir haben 500 Leute, die sich ausschließlich damit beschäftigen, dass die Data Pipelines funktionieren. Und das zweite Alleinstellungsmerkmal ist die Anzahl der Datenquellen, die wir abdecken: Jetzt sind es über 450. Und dazu haben wir eine Technologie entwickelt, mit der wir pro Jahr bis zu 300 hinzufügen können. Die Abdeckung der Datenquellen und der Destinationen inklusive Data Lakes und die Tatsache, dass die Endanwender bei den Unternehmen alles selbst machen und betreiben können, sowie die hohe Verfügbarkeit von 99,95 Prozent sind Dinge, die bei uns herausstechen. Dazu kommt die Einfachheit, mit der man das alles realisieren kann. Einige simple Klicks lassen die Daten fließen. So wie es unser Slogan aussagt: »As simple and reliable as electricity.« Es funktioniert einfach!