
Daten werden immer wichtiger für den Erfolg von Unternehmen. Die richtige Information zum richtigen Zeitpunkt ist von immenser Bedeutung für den heutigen und zukünftigen Erfolg von Geschäftsmodellen.
Durch Edge Analytics muss die Analytics-Fähigkeit und die Rechenleistung ein Stück weit in Richtung der IoT-Geräte verlagert werden. Der Wertanteil von Machine Learning und Künstlicher Intelligenz an Produkten und Diensten wird sich deutlich erhöhen und zum Teil auch einige Produkte oder Dienste überhaupt erst möglich machen. Auf Basis der Data Integration Hubs werden sich Marktplätze für Daten etablieren, die dann Lizenzen für die Nutzung von Daten ermöglichen. Die Erstellung und das Management von unternehmensweiten Taxonomien und Ontologien ist eine der wichtigen Aufgaben in der Agenda zur Datenstrategie. Zudem sind globale Strategien im Bereich der Data Provenance wichtig, damit zukünftig alle Anforderungen an rechtliche Rahmenbedingungen erfüllt werden können und die Kontrolle über die eigenen Daten (Datenhoheit) erhalten bleibt.
- Edge Analytics
Am Ende des Internets beginnt die reale Welt. Und eben dort werden auch viele Daten durch IoT-Endgeräte erfasst. Die Anzahl dieser Sensoren und Geräte vervielfacht sich mit einer steigenden Geschwindigkeit. Mehr Geräte erfassen mehr Daten und die sollten analysiert und für einen Mehrwert aufbereitet werden. Dies kann im Rechenzentrum oder in der Cloud passieren, jedoch ist es nicht für alle Daten, die erhoben werden, notwendig eine nachhaltige Speicher- und Archivierungsstrategie zu verfolgen. Von vielen Daten ist lediglich die Information notwendig, die zu einer Entscheidung für einen spezifischen Anwendungsfall beiträgt.
Damit Daten vor Ort möglichst nahe an der realen Welt, also beispielsweise am Sensor direkt, analysiert werden können, muss die Rechenkapazität vor Ort und Stelle zur Verfügung stehen. Diese Aufgabe versuchen zum Teil bereits Produkte von IBM und Cisco rund um das Thema Fog Computing beziehungsweise Edge Computing zu lösen. Dennoch wird sich gerade in dem Umfeld der Digitalisierungsstrategien der Unternehmen mehr und mehr die Notwendigkeit abzeichnen, die Information aus den Datenströmen aufbereitet an das Rechenzentrum zu übermitteln.
Dies lässt sich auch sehr gut mit den neuesten Ansätzen im Cloud-Service-Bereich zum Thema Serverless beziehungsweise Event-basierter Architekturen vereinen. Denn das Event wird bereits frühzeitig in der Nähe des IoT-Gerätes erfasst und dann an die Cloud-Plattform übermittelt. Dort kann dann die hinterlegte Funktion die Transformation dieser Informationen durchführen und auch entsprechend das Event archivieren. Die eingetroffenen Events können dann im Self-Service-Modell weiter analysiert werden.
Für Unternehmen bietet dieser Ansatz auch viele Möglichkeiten von neuen Geschäftsmodellen. Wenn wir unsere Smartphones als solch einen IoT-Endpunkt definieren, dann finden wir heute bereits genügend Rechenleistung, um die Analyse der Daten vor Ort durchzuführen für viele Anwendungsszenarien. Ein Anwendungsbeispiel ist die Synchronisierung von gestreamter Musik mit dem Lauftempo des Nutzers. In diesem Szenario würde die verzögerte oder auch im Nachgang durchgeführte Analyse der Daten keinen Mehrwert bieten und auch kein Geschäftsmodell darstellen. Darum muss die Analytics-Fähigkeit und die Rechenleistung ein Stück weit in Richtung der IoT-Geräte verlagert werden.
- Machine Learning & Künstliche Intelligenz
Machine Learning und Künstliche Intelligenz haben in 2016 den IT-Mainstream und die Gesellschaft erreicht. Die Diskussionen in vielen Medien bringen die Pflicht zur Auseinandersetzung mit diesen Technologien mit sich. Unternehmen müssen hier schnellstens den geeigneten Zugang finden und die Talente entsprechend fördern oder ausbilden. In vielen Bereichen von Produkten und Dienstleistungen sind bereits Technologien aus dem Bereich des Machine Learning im Einsatz und dies wird sich noch deutlich steigern.
Der Wertanteil von Machine Learning an Produkten und Diensten wird sich deutlich erhöhen und zum Teil auch einige Produkte oder Dienste überhaupt erst möglich machen. Während auf der Anwenderseite die Unternehmen die Fragen auf strategischer Ebene schnell beantworten müssen, sind auf Anbieterseite von Big Data, Cloud Computing und Analytics mehr Dienste und Produkte erforderlich, die der Demokratisierung von Machine Learning Technologien förderlich sind. Denn nicht jedes Unternehmen wird in der breiten Masse ein Verständnis für Daten und Machine Learning umsetzen können, wie es beispielsweise bei den großen Internetkonzernen oder Softwareherstellern der Fall ist.
- Data Integration Hubs
Das Thema IoT und auch Internet of Everything scheint schneller und deutlich spürbarer in den Unternehmen und auch in den Privathaushalten anzukommen, als es beispielsweise bei der Cloud der Fall war. Schon jetzt gibt es Ansätze Informationen auf Basis von Ereignissen durch die unterschiedlichsten Systeme zu führen, damit am Ende dann die Lampe eingeschaltet wird oder der Roboter mit dem Schweißen aufhört.
Was im privaten Umfeld noch mit Ereignis-basierten Workflow-Plattformen, wie beispielsweise IFTTT erfolgen kann, bringt im Unternehmensalltag mehr Komplexität und erfordert auch mehr Kontrolle und Management. Die logische Konsequenz ist die Etablierung von Data Integration Hubs. Dabei handelt es sich um Plattformen auf denen Daten ausgetauscht werden können. Dies kann auf globaler Ebene ein einzelnes Unternehmen betreffen oder auch in Richtung Mittelstand gedacht direkt die Kooperation über die unterschiedlichen Branchen hinweg erst ermöglichen. Dabei kann der Data Integration Hub Teil eines öffentlichen Netzwerkes sein oder aber auch sich einer privaten Verbindung bedienen, damit die Daten sicher und kontrolliert ausgetauscht werden können.
In einigen Branchen, beispielsweise der Automobilindustrie, gibt es bereits Ansätze, die in diese Richtung gehen. Jedoch wird der Data Integration Hub aufgrund der Entwicklungen im IoT-Umfeld branchenübergreifend und global benötigt werden. Im nächsten Schritt werden sich dann auf Basis der Data Integration Hubs Marktplätze für Daten etablieren, die dann Lizenzen für die Nutzung von Daten ermöglichen.
- Enterprise Taxonomy und Ontologie Management
Machine-Learning-Algorithmen brauchen ebenso wie wir Menschen Kontext zu den erhobenen und zu analysierenden Daten. Ohne diesen fällt es schwer unter dem Begriff »Jaguar« die korrekte Intention bei einer Frage abzuleiten. Das semantische Verstehen von Inhalten ist nach wie vor eine wichtige Aufgabe. Auch wenn Algorithmen, Plattformen und Tools den Zugang zu einer Datenanalyse vereinfachen und auch Machine-Learning-Technologien immer mehr Menschen zur Verfügung gestellt werden können, so bleibt der Kontext und die Anwendung doch auf die verfügbaren Datenbasis begrenzt.
Die Erstellung und das Management von unternehmensweiten Taxonomien und Ontologien ist daher eine der wichtigen Aufgaben in der Agenda zur Datenstrategie. Nur wenn der Kontext des Unternehmens entsprechend aufbereitet wird, kann die Analyse zu einem erfolgreichen Geschäftsmodell führen. Dies muss nicht nur die interne Verwendung dieser Informationen einschließen. Denn eine Integration einer Schnittstelle zu einem Data Marketplace auf einem Data Integration Hub kann auch die lizenzierte Nutzung für externe Kunden oder Partner einschließen.
- Data Provenance Management – Dynamic Data Mobility and Tracing
Die Wichtigkeit eines Data Provenance Management beim Umgang mit Daten wird sich im nächsten und in den kommenden Jahren noch deutlich mehr in den Vordergrund drängen. Denn die umfassende Kenntnis und Dokumentation über die Herkunft, die Transformation und den Fluss der Daten ist elementar, um Daten auch zukünftig rechtskonform verarbeiten und über Unternehmensgrenzen hinweg nutzen zu können.
Hier ergeben sich beispielsweise aus der General Data Protection Regulation (GDPR) der Europäischen Union oder zu deutsch der EU-Datenschutz-Grundverordnung (EU-DSGVO) neue Vorgaben und Regeln für Unternehmen, die Technologie-seitig teilweise nur schwer abbildbar sind. Was für die lokale Applikation vielleicht noch leicht nachvollziehbar ist, wird umso schwerer, je mehr Datenquellen miteinander verknüpft werden.
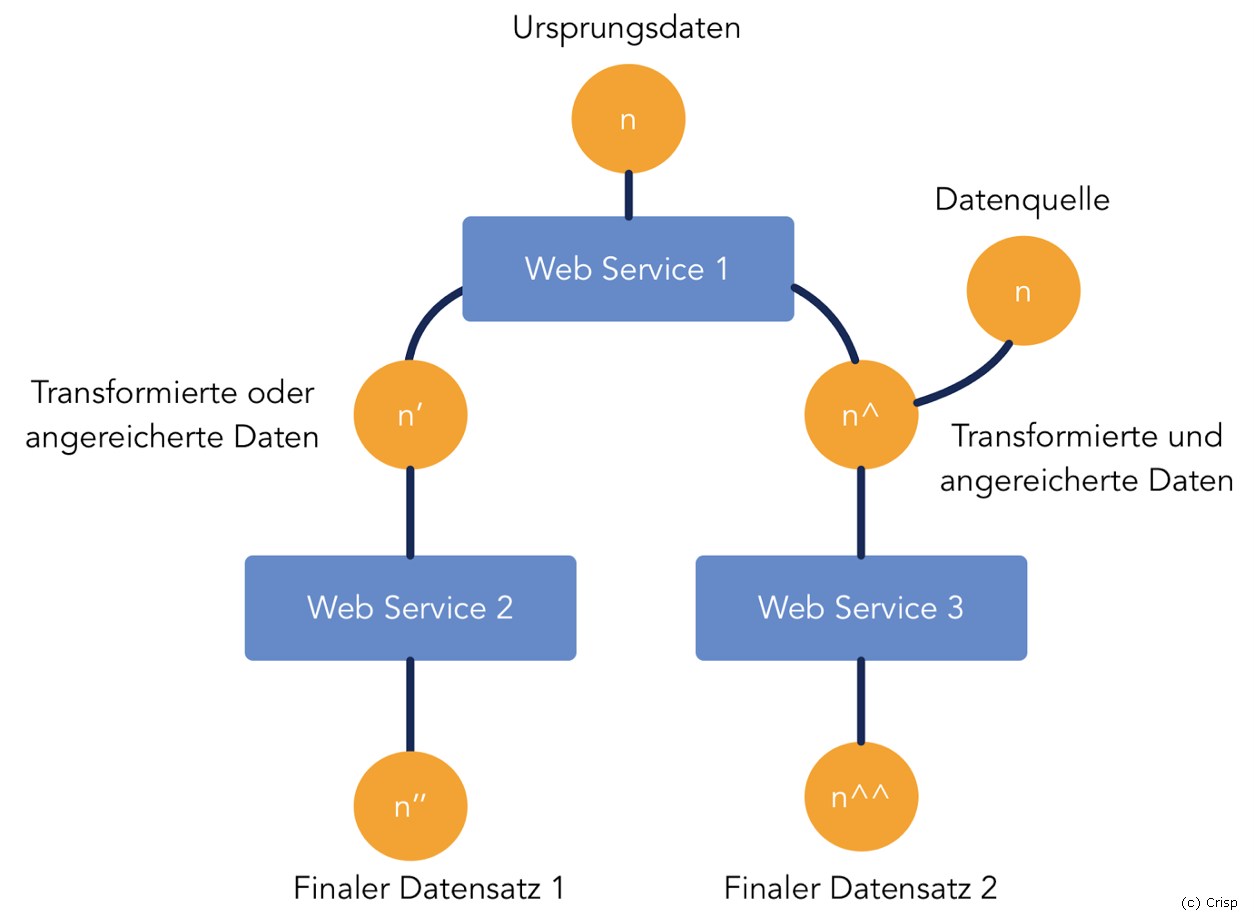
Doch nur durch die Kombination von vielen unterschiedlichen Datenquellen lässt sich oftmals ein Mehrwert oder das Produkt selbst erst generieren. Bei der Nutzung von API-Aufrufen ist die Nachvollziehbarkeit noch weitestgehend abbildbar, jedoch sieht es bei Big-Data-Projekten und IoT-Szenarien schon anders aus. Daten werden aus unterschiedlichen Quellen geladen, aggregiert, analysiert und dann aufbereitet und wieder mit anderen Quellen vermischt. Am Ende der Kette ist es dann schon relativ schwer zu sagen, woher die einzelne Information ursprünglich stammt beziehungsweise aus welchen Daten sie sich zusammensetzt.
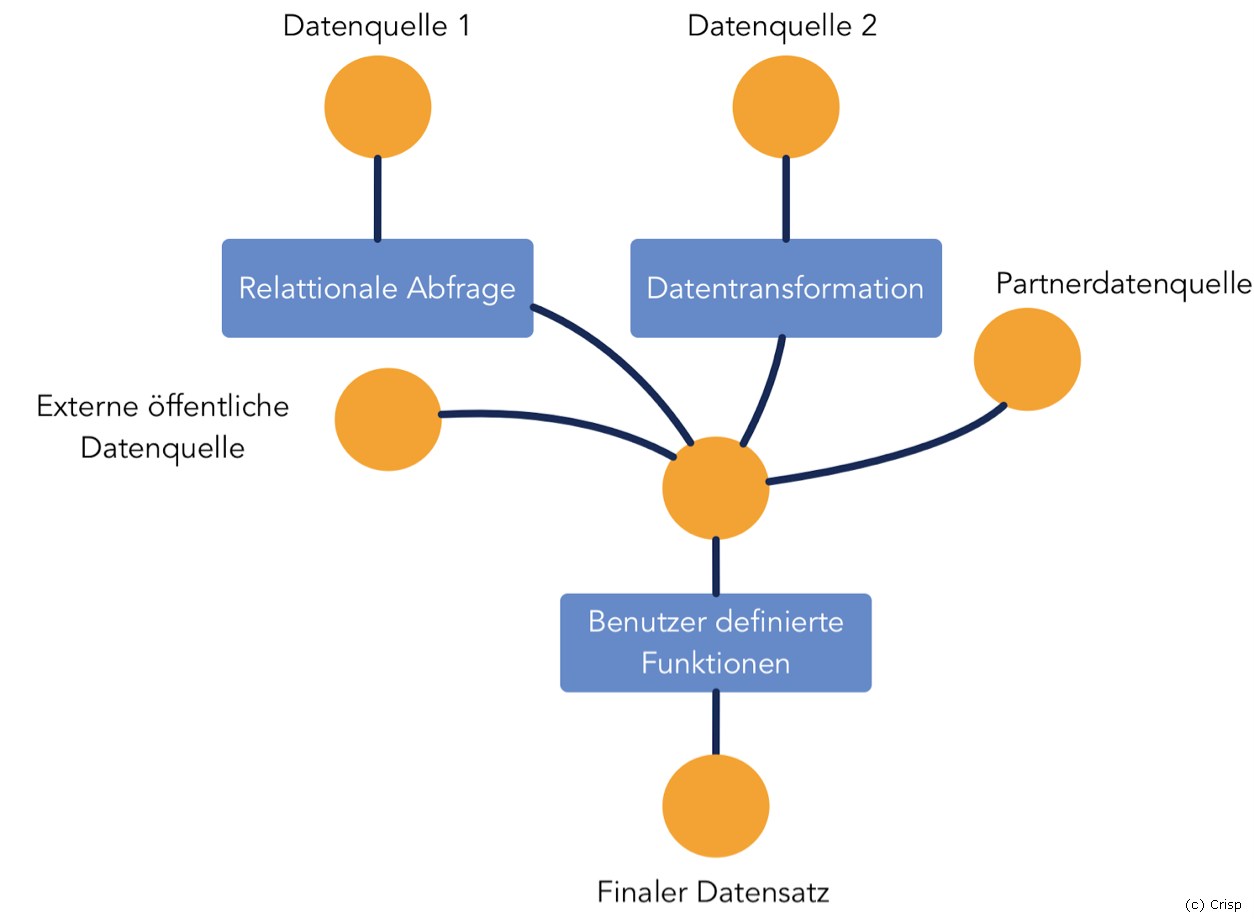
Mindestens eine Komplexitätsstufe mehr erreicht man, wenn dann noch der Austausch der Daten über die Unternehmensgrenzen hinweg ermöglicht wird. Hier geht neben der Dokumentation, welcher Partner gerade welche Daten liest oder schreibt, auch die Nachvollziehbarkeit des Informationsflusses schnell verloren. Daher sind globale Strategien im Bereich der Data Provenance wichtig, damit zukünftig alle Anforderungen an rechtliche Rahmenbedingungen erfüllt werden können und auch die Kontrolle über die eigenen Daten (Stichwort Datenhoheit) auch erhalten bleibt.
Björn Böttcher, Crisp Research, www.crisp-research.com
Neue Strategien zum Datenschutz setzen sich nur langsam durch
IT-Security-Strategie erzeugt intensivere Kundenbindung, Wettbewerbsvorteile, höhere Produktivität
Die Digitalisierung muss in die Unternehmensstrategie eingebunden werden
Datenvirtualisierung: Überbrückung der Technologielücke mit Hybrid-IT
Tipps für den Personalchef: Strategien für den Kulturwandel in Unternehmen
Unternehmen sind schlecht auf die neue EU-Datenschutz-Grundverordnung vorbereitet
Content Marketing der Zukunft kann nur datengesteuert erfolgen
Schutz vertraulicher Daten: Phishing bedroht Unternehmen und private Internetnutzer