
Illustration: Absmeier, Ewirz
Die Speicherinfrastruktur spielt in heutigen, datengesteuerten Unternehmen eine immer noch zunehmend wichtige Rolle. Das betrifft nicht zuletzt Sicherheit und Verfügbarkeit der Daten. Hier spielen Funktionen wie Datenreplikation und schnelle Disaster Recovery eine große Rolle. Oft zeigen sich Menschen beeindruckt von den schieren Datenmengen, die heutige Storage-Systeme im Vergleich zu früheren Zeiten speichern und bereitstellen müssen. Die wesentlichen Fortschritte wurden allerdings bei Datenverfügbarkeit und Wiederherstellungszeiten erzielt und hier insbesondere bei Widerherstellungszeitpunktziel (Recovery Time Objective: RTO) und Wiederherstellungspunktziel (Recovery Point Objective: RPO). Ein Blick zurück verdeutlicht, wie weit wir bei diesen Faktoren gekommen sind und wie wichtig permanente Weiterentwicklungen sind, um die wachsenden Anforderungen von Unternehmen zu erfüllen.
Kurzer Blick zurück
Die Idee, Daten durch das Anfertigen einer Kopie an einem entfernten Ort zu schützen, hat eine lange und reiche Geschichte. Die Grundlage ist die Erstellung von Sicherungskopien, die dann an einen entfernten Standort transportiert wurden. Die Sicherungskopie konnte zur Wiederherstellung der Daten verwendet werden, falls die Primärdaten jemals kompromittiert wurden. Jahrzehntelang waren ungeschützte Platten das Medium der Wahl für primäre Unternehmensdaten, während Bänder als Speichermedium der Wahl für Sicherungskopien fungierten. In dieser guten, alten Zeit wurde das RTO, also die Zeit, die vom Zeitpunkt des Schadens bis zur vollständigen Wiederherstellung der Systeme vergehen darf, gewöhnlich in Tagen berechnet. Das RPO legt fest, wie viel Datenverlust ein Unternehmen gegebenenfalls hinzunehmen bereit ist. Entsprechend wird der Zeitraum festgelegt, in dem Sicherungskopien erstellt werden. Oftmals wurde auch das RPO in Tagen definiert. In der Praxis bedeutete dies, dass im Falle eines Schadens häufig die Daten von Tagen verloren gingen.
Heutzutage kann kein Unternehmen sich RPO oder RTO im Maßstab von Tagen erlauben. In einer perfekten Welt sollte das RTO gleich Null sein – sofortiger Dauerbetrieb nach einem Schaden, ohne dass menschliches Eingreifen erforderlich ist. Das perfekte RPO liegt ebenfalls bei Null – kein Datenverlust trotz eines Problems. Doch wie realistisch ist das?
Meilensteine
Tatsächlich sind sowohl ein RTO von Null als auch ein RPO von Null heute realistisch. Dass dem so ist, haben wir einer Reihe wichtiger Entwicklungen zu verdanken, die verschiedene Vorreiter der Storage-Branche beigetragen haben.
Bereits 1994 führte die Digital Equipment Corporation (DEC) die OpenVMS Multi-Datacenter Facility (MDF) ein, die später in Business Recovery Server (BRS) umbenannt wurde. Dabei handelt es sich um eine entfernungsabhängige synchrone Implementierung von OpenVMS-Clustern. Sie ermöglicht es einem Rechenzentrum, den Betrieb aufrechtzuerhalten, wenn das andere ausfiel, und bot die weltweit erste Datenschutzlösung mit Null RPO und nahezu Null RTO (bei einem maximalen Abstand der Rechenzentren von ca. 40 Kilometern). MDF war serverbasiert und erforderte, dass die gesamte Hardware und Software von DEC stammte.
Ebenfalls bereits 1994 führte die EMC Corporation die Symmetrix Remote Data Facility (SRDF) ein, die weltweit erste speicherbasierte synchrone Datenreplikationslösung auf Abstand, die in der Lage war, für mehrere Server ein RPO von Null bei einem RTO von nahezu Null zu gewährleisten. Im Laufe des nächsten Jahrzehnts folgten alle großen Speicheranbieter dem Beispiel von EMC und führten ihre eigenen Replikationsprodukte ein.
2010 lieferte EMC Corporation mit VPLEX eine weitere Innovation, die weltweit erste Technologie, die endlich einen Datenschutz mit RPO Null und RTO Null innerhalb bestimmter Entfernungen bietet. Ein Großteil der technischen Grundlage von VPLEX stammte aus der Übernahme von Yotta Yotta durch EMC im Jahr 2008.
2017 war Pure Storage das erste Unternehmen neben Dell EMC, das mit ActiveCluster eine synchrone Replikationslösung mit Null RPO und Null TRO auf den Markt brachte. 2019 folgte Infinidat mit Active-Active-Replikation für seine InfiniBox-Stysteme, ebenfalls eine synchrone Replikationslösung mit Null RPO und Null RTO bietet, allerdings weniger kostspielig und komplex als die Angebote von Dell EMC und besser skalierbar als die Lösung von Pure.
In diesem Jahr schließlich hat Infinidat seine Lösung zur asynchronen Replikation mit niedrigem RPO (4 Sekunden Zykluszeit) und Active-Active Replikation kombiniert. Hierdurch stehen nun Optionen für optimales RPO und RTO in Replikationslösungen mit drei oder mehr Standorten zur Verfügung.
Stand der Technik
Bei der genannten asynchronen Replikation der beiden synchronen Systeme zu einem dritten (oder vierten) Standort kann ein RPO im einstelligen Sekundenbereich gewährleistet werden. Dies ist derzeit das Optimum des Machbaren. Die meisten Infrastrukturen mit asynchroner Replikation über große Abstände erreichen bestenfalls ein RPO im Minutenbereich. Wir haben definitiv einen langen Weg zurückgelegt von den Tagen, in denen sich Unternehmen mit Sicherungskopien auf Bändern und RPO und RTO im Bereich von Tagen zufriedengegeben haben. In der heutigen Zeit sind ist viele Anwendungen nicht nur ein RPO von Tagen nicht mehr akzeptabel, sondern auch ein RPO von Minuten ist häufig nicht mehr gut genug. Genau einen solchen weisen allerdings Infrastrukturen auf, die einen RPO lediglich zwischen synchronen Rechenzentren bieten und nicht auch für die asynchronen.
Hans Hallitzky, Sales Manager DACH bei INFINIDAT
RPO, RTO und Backup verstehen – Kennzahlen und Kriterien von Datensicherung
Da Unternehmen vermehrt auf geschäftskritische IT-Dienste angewiesen sind, sind Infrastruktur und Anwendungen nach Meinung von Rubrik zu wichtigen strategischen Imperativen geworden. Der junge Anbieter von Cloud Data Management fordert mehr Aufklärung.
»Ausfallzeiten und Datenverluste können enorme geschäftliche und finanzielle Auswirkungen haben, die mit einer effektiven Datensicherungsstrategie zwingend minimiert werden müssen«, erklärt Roland Stritt, Director Channels EMEA bei Rubrik. »Bei der Planung einer Datensicherungsstrategie oder eines Disaster-Recovery-Plans sind mehrere Kriterien bezüglich der geschäftlichen Auswirkungen verschiedener Anwendungen und Workloads zu berücksichtigen.«
Eine Business-Impact-Analyse (BIA) kann helfen, die Auswirkungen und Konsequenzen einer Unterbrechung des Geschäftsbetriebs sowohl finanzieller als auch nichtfinanzieller Art zu beurteilen und abzuwägen. Diese Ergebnisse können Unternehmen dabei helfen, ihre Verfügbarkeits-Service-Level-Agreements (SLAs) oder den vom Kunden erwarteten Service-Level zu bestimmen. Meistens werden mehrere SLAs definiert, die den verschiedenen Stufen der Kritikalität entsprechen, die mithilfe der BIA ermittelt wurden.
Beispielsweise werden die folgenden SLAs häufig verwendet:
- 99 Prozent oder »Two 9s« entsprechen 3 Tagen 15 Stunden und 36 Minuten Ausfallzeit pro Jahr.
- 99,9 Prozent oder »Three 9s« entsprechen 8 Stunden 45 Minuten und 36 Sekunden Ausfallzeit pro Jahr.
- 99,99 Prozent oder »Four 9s« entsprechen 52 Minuten und 34 Sekunden Ausfallzeit pro Jahr.
Verfügbarkeits-SLAs werden dann von der IT-Abteilung oder dem Dienstanbieter in vertretbare Datenverluste und ungeplante Ausfallzeiten umgerechnet. Die Recovery Point Objective (RPO) und Recovery Time Objective (RTO) sind zwei der wichtigsten Konstrukte eines SLAs und repräsentieren diese Ziele.
Recovery Point Objective
Die RPO stellt die maximale Datenmenge dar, die ein Unternehmen sich leisten kann, zu verlieren. Um genauer zu sein, beschreibt die RPO den Zeitpunkt, zu dem sich das Unternehmen bei der Wiederherstellung den größten Rückstand leisten kann. Aus datenschutzrechtlicher Sicht entspricht dies in der Regel der Häufigkeit, mit der Daten gesichert oder repliziert werden müssen. Diese kann in Tagen, Stunden, Minuten oder sogar Sekunden ausgedrückt werden.

Im folgenden Beispiel beträgt die vereinbarte Verfügbarkeits-SLA 99 Prozent, was etwas mehr als 3,5 Tage tolerierter Ausfallzeit entspricht. Da das SLA sowohl die RPO als auch die RTO umfasst, muss die Summe der beiden kleiner als 3,5 Tage sein. Um diesem SLA gerecht zu werden, wurde eine RTO und eine RPO von 24 Stunden definiert. Es ist möglich, den ausgefallenen Workload aus dem letzten Backup wiederherzustellen, das weniger als 24 Stunden alt ist. Daten, die zwischen der letzten Sicherung und dem Fehlerereignis erstellt oder geändert wurden, gehen verloren. Da es sich jedoch um Daten im Wert von weniger als 24 Stunden handelt, wird die Recovery Point Objective erreicht.
Im folgenden Beispiel beträgt die definierte RPO noch 24 Stunden. Am Mittwoch ist ein Fehler aufgetreten, aber die Daten konnten nicht aus dem letzten Backup, das am Dienstagabend erstellt wurde, wiederhergestellt werden. Der Administrator muss die Arbeitslast aus dem Backup des Vortages wiederherstellen, was bedeutet, dass mehr als 24 Stunden Daten verloren gegangen sind. Das Ziel wird in diesem Fall nicht erreicht.
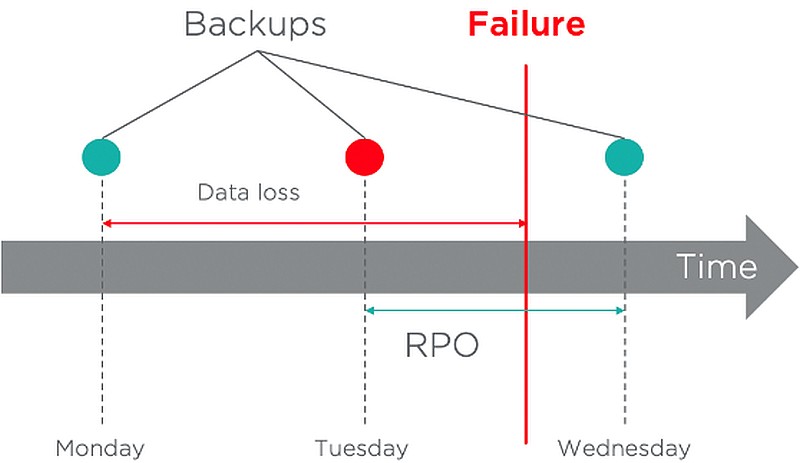
Um dieses Risiko zu minimieren, könnte die Sicherungshäufigkeit so angepasst werden, dass sie häufiger auftritt, während eine RPO von 24 Stunden eingehalten wird.
Die meisten Workloads, Anwendungen oder Datensätze mit einer niedrigen bis durchschnittlichen Kritikalität haben eine SLA von 99 Prozent oder weniger und eine RPO von 24 Stunden oder mehr. Es ist sehr häufig, dass solche Workloads ein- bis zweimal täglich gesichert werden.
Für kritischere Workloads mit einer SLA von 99,9 Prozent oder mehr ist es notwendig, die RPO auf wenige Stunden, ja sogar Minuten oder Sekunden zu reduzieren, um konform zu sein.
Recovery Time Objective
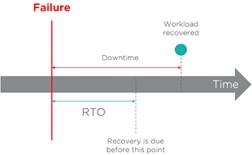
Die RTO entspricht der maximalen Zeit, in der ein ausgefallener Workload wiederhergestellt werden muss.
Einige Anwendungen und Dienste können jedoch einige Zeit in Anspruch nehmen, oder Workloads können nach der Wiederherstellung zunächst in einem verschlechterten Modus neu gestartet werden. In solchen Fällen kommt die zusätzliche Zeit, die benötigt wird, bis die wiederhergestellten Workloads einsatzbereit sind, zur RTO hinzu und wird als Work Recovery Time (WRT) bezeichnet. Die Addition von RTO und WRT definiert die maximal tolerierbare Ausfallzeit, bezeichnet als Maximum Tolerable Downtime (MTD).
In der folgenden Abbildung beträgt das vereinbarte SLA noch 99 Prozent und die RTO 24 Stunden. Der fehlerhafte Workload wird in weniger als 24 Stunden wiederhergestellt. Das Ziel der Wiederherstellungszeit wird erreicht.

Im Gegenteil dazu wird in der nächsten Abbildung das Ziel nicht erreicht, da die Wiederherstellung des ausgefallenen Workloads länger dauerte als die definierte RTO.
Es gibt mehrere Faktoren, die die Wiederherstellungszeiten beeinflussen, einschließlich:
- Umfang des Fehlers. Ausfälle können auf verschiedenen Ebenen einer Infrastruktur auftreten. Es ist schneller und einfacher, einzelne Workload-Ausfälle zu beheben, als beispielsweise einen Speicher-Array-Ausfall oder einen kompletten Rechenzentrumsausfall. Darüber hinaus gibt es mehrere Möglichkeiten, die Situation zu überwinden, wenn kritische Hardware wie ein Speicher-Array ausfällt. Das Array selbst kann repariert oder ersetzt werden, oder es kann ein Failover auf eine Disaster-Recovery-Infrastruktur ausgelöst werden. Letzteres ermöglicht wesentlich kürzere Wiederherstellungszeiten als Ersteres.
- Menge und Art der wiederherzustellenden Daten. Im Allgemeinen gilt: Je größer die wiederherzustellende Datenmenge, desto länger ist die Wiederherstellung. Aber gleichzeitig dauert es in der Regel kürzer, einige wenige Dateien wiederherzustellen, als einen ganzen Computer oder eine große Datenbank.
- Backupspeicherleistung. Oftmals ist Backup-Speicher, auch als Sekundärspeicher bezeichnet, kostengünstiger als Produktionsspeicher und bietet nicht die gleiche Leistung. Die Wiederherstellungszeiten hängen davon ab, was der Backup-Speicher liefern kann.
- Netzwerkperformance. In den meisten Fällen laufen Datenübertragungen für Wiederherstellungsvorgänge über das Netzwerk. Unternehmen, die Ethernet-Netzwerke mit 10 Gbit/s (oder mehr) für Backup- und Wiederherstellungszwecke verwenden, profitieren von mehr Bandbreite, was wiederum dazu beiträgt, die Wiederherstellungszeiten zu verkürzen. Wenn Daten über ein von verschiedenen Streams gemeinsam genutztes Netzwerk wiederhergestellt werden müssen, kann die Wiederherstellung aufgrund der geringeren verfügbaren Bandbreite länger dauern.
RPO und RTO: Der Ansatz
Rubrik setzt sich seit langem dafür ein, die Datensicherung einfach, sicher, zuverlässig und schnell zu gestalten. Damit Unternehmen ihre RPOs verbessern können, bietet Cloud Data Management (CDM) eine Reihe von Technologien und Funktionen, die helfen, Backup-Fenster zu reduzieren und die Backup-Frequenz zu erhöhen:
- Ingestion zur Optimierung der Speicherung. Rubrik bietet ein skalierbares und verteiltes Dateisystem, das sich über alle Festplatten im Cluster erstreckt. In Kombination mit der Löschkodierung ist die Aufnahmeleistung vergleichbar mit der von Flash-Speichern.
- Parallele Ingestion. Cluster bestehen aus mindestens drei bis vier Knoten, und die Lösung skaliert, indem sie weitere Knoten zu demselben Cluster hinzufügt, in dem alles verteilt ist. Jeder Knoten im Cluster kann mehrere Workloads gleichzeitig sichern. Je größer der Cluster, desto mehr Daten können parallel aufgenommen werden und desto kürzer ist das Backup-Fenster.
- Inkrementell. Sobald das erste vollständige Backup abgeschlossen ist, werden nur noch neue und geänderte Daten gesichert. Dies trägt auch zu kürzeren Backup-Fenstern bei und reduziert den erforderlichen Bandbreitenverbrauch des Netzwerks.
Die erweiterte Integration mit Microsoft SQL Server und Oracle wird unterstützt. Diese Workloads werden auf Anwendungsebene mit Hilfe des Backup Service (RBS) gesichert, der auf den entsprechenden Servern eingesetzt wird. Dies ermöglicht eine periodische anwendungskonsistente Sicherung einzelner oder aller Datenbanken, aber auch eine Sicherung von Transaktionsprotokollen für SQL Server und Archivprotokollen für Oracle.
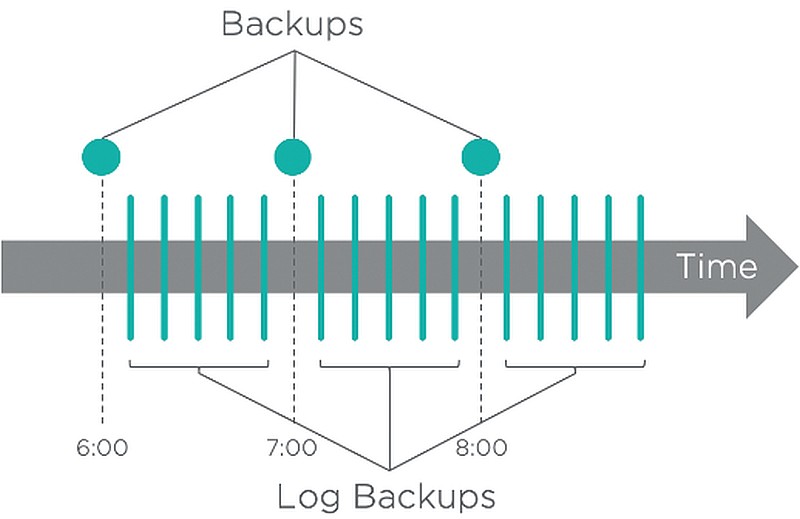
Die erweiterte Protokollverarbeitung ermöglicht einen viel häufigeren Point-in-Time-Backup der kritischsten Datenbanken, bei denen die RPO viel geringer ist, in der Regel bis hinunter auf wenige Minuten. Eine solche Verarbeitung kann als nahezu kontinuierliche Datensicherung bezeichnet werden. Die folgende Abbildung zeigt ein Beispiel, bei dem anwendungskonsistente Backups jede Stunde und Log-Sicherungen alle zehn Minuten durchgeführt werden.
Wenn eine Multi-Terabyte-VM, virtuelle Festplatte oder Datenbank wiederhergestellt werden muss, dauert es in der Regel sehr lange, bis sie wiederhergestellt und in der Produktionsumgebung verfügbar ist. Um dieses Problem zu lösen, bietet Rubrik diese Technologien an:
- Instant Recovery. Speziell für vSphere und Hyper-V-VM-Wiederherstellung kann diese Funktion ein VM-Image direkt aus den auf der Appliance gespeicherten Backup-Daten veröffentlichen und aktivieren. Diese Art der Wiederherstellung ist destruktiv, d.h. das neue VM-Objekt, das ik gebootet wurde, ersetzt das ursprüngliche. Instant Recovery eliminiert herkömmliche Wiederherstellungszeiten und bringt nahezu Null RTO auf die kritischsten VMs.
- Live Mount. Ähnlich wie bei der Sofortwiederherstellung (Instant Recovery) kann Live Mount ein komplettes VM-Image, ein einzelnes VMDK und eine einzelne SQL- oder Oracle-Datenbank von der Appliance zurück in die Produktionsumgebung veröffentlichen. Wenn ein Live-Mount ausgeführt wird, wird der wiederhergestellte Workload als neues Objekt veröffentlicht und nicht überschrieben.
- Fast Storage. Jedes Cluster bietet genügend Speicherleistung, um mehrere gleichzeitige Live Mounts oder Instant Recoveries zu ermöglichen. Insbesondere verfügt jeder Knoten über ein Flash-Laufwerk, das zum Cachen von Daten verwendet wird, die von Instant Recovery und Live Mount veröffentlicht werden.
- Fast Networking. Appliances werden mit schnellen und modernen Netzwerkschnittstellenkarten (10 Gbit/s und mehr) in jedem Knoten geliefert. Dies ergänzt den schnellen Speicher und die Live-Mount-Technologien, um die schnellstmögliche Wiederherstellung zu ermöglichen.
Fazit
»Wenn RPOs und RTOs für alle Workloads und Anwendungen sowie für die Kosten von Ausfallzeiten für ein bestimmtes Unternehmen bekannt sind, können die richtigen Entscheidungen getroffen werden, um Daten angemessen zu sichern«, so Roland Stritt von Rubrik. »Die IT-Abteilung hat die Aufgabe, die richtigen Technologien auszuwählen und eine geeignete Strategie rund um Datensicherung und Disaster Recovery zu entwickeln.«
481 search results for „Backup“
NEWS | CLOUD COMPUTING | IT-SECURITY | ONLINE-ARTIKEL | SERVICES
Europäische Unternehmen ignorieren beim Daten-Backup die Cloud

Daten, Daten, Daten! Nur wohin damit, wenn es um deren Schutz geht? Die Cloud scheint bei europäischen Unternehmen kein adäquate Backup-Lösung zu sein. Sie vertrauen in der Mehrheit immer noch ganz traditionell auf Plattformanbieter wie Microsoft, um ihre Daten zu schützen. So offenbart es eine aktuelle Studie von Barracuda Networks, die die Antworten von 432…
NEWS | PRODUKTMELDUNG
Enge Integration mit geschäftskritischen Anwendungen: Veeam erhält Backup-Zertifizierung für SAP HANA

Neue Veeam Availability Suite 9.5 Update 4 bietet zertifiziertes Plug-In für SAP HANA. Integration mit SAP HANA verbessert Backup und Disaster Recovery. Vollständige Backup-Kontrolle für SAP-Administratoren. Veeam Software, Anbieter von Backup-Lösungen für intelligentes Datenmanagement, hat jetzt für das neue Veeam Plug-In für SAP HANA die offizielle Zertifizierung »SAP Certified Integration for SAP HANA« erhalten.…
NEWS | IT-SECURITY | LÖSUNGEN
Ein Backup für Insektengitter

Es ist die Natur des Menschen, sich vor Ungemach zu schützen und so konstruiert, baut und vertreibt die Spengler und Meyer GmbH, besser bekannt unter »Die Muggergittermacher«, als eines der erfolgreichsten Unternehmen seiner Branche, Insektenschutzgitter für private Haushalte und Geschäftsgebäude. Seit fast 30 Jahren schützt das Unternehmen dadurch Menschen vor lästigen Fliegen oder Insektenstichen bei…
NEWS | INFRASTRUKTUR | AUSGABE 11-12-2018
Eigenverantwortung bei der Datensicherung – Das Backup wird demokratisch

Backups sollten von den Mitarbeitern erstellt werden, die täglich mit den Daten arbeiten.
NEWS | BUSINESS PROCESS MANAGEMENT | INFRASTRUKTUR | IT-SECURITY | ONLINE-ARTIKEL | RECHENZENTRUM | TIPPS
Geschäftskritische Downtime durch moderne Backups minimieren – Schnell zurück zum Tagesgeschäft

Unternehmen generieren mehr Daten als je zuvor: Laut IDC soll bis zum Jahr 2020 eine Datenmenge von 40 Zettabytes entstehen. Neben dem Volumen nimmt auch die Bedeutung der Daten zu. Die intelligente Nutzung von Daten hat sich als unerlässlich für die Wettbewerbsfähigkeit, den Umsatz und das Tagesgeschäft von Unternehmen auf der ganzen Welt erwiesen. …
NEWS | CLOUD COMPUTING | INFRASTRUKTUR | RECHENZENTRUM | SERVICES
BaaS im Aufwind – Steigende Akzeptanz der Cloud verändert Backup-Anforderungen

Die zunehmende Akzeptanz der Cloud seitens der Unternehmen verändert die Rolle der Rechenzentren: Sie wandeln sich zu betriebskostenorientierten Einrichtungen, die für As-a-Service-Modelle optimiert sind. Das hat nach Angaben von Rubrik »auch spürbare Folgen für den Bedarf und die Realisierung von Backup-Lösungen, die vermehrt im »As-a-Service«-Modell genutzt werden. »Für viele Unternehmen ist Backup-as-a-Service (BaaS) zu…
NEWS | BUSINESS PROCESS MANAGEMENT | CLOUD COMPUTING | INFRASTRUKTUR | IT-SECURITY | OUTSOURCING | ONLINE-ARTIKEL | SERVICES
Backup: Von lästiger Pflicht zur nützliche Ressource

Cloud Data Management macht aus dem einst ungeliebten Daten-Backup eine wertvolle Ressource für Unternehmen. Backup- und Recovery-Lösungen hatten lange Zeit keinen guten Ruf. Der Markt stagnierte, war geprägt von den immergleichen Anbietern, welche die immer gleichen Lösungen verkauften: Lösungen, die die Benutzer einschränkten. Die Verwaltung und Sicherung von Geschäftsdaten und persönlichen Daten war eine langwierige…
NEWS | IT-SECURITY | TIPPS
Jedes Backup ist besser als gar keins
Jedes Jahr am 31. März ist »World Backup Day«: Dieser Tag wurde von einer nach eigenen Angaben unabhängigen Kampagne erkoren, um auf die Wichtigkeit regelmäßiger Datensicherungen hinzuweisen. Unter Windows 10 funktioniert das Backup ganz einfach über die Systemsteuerung. Dort kann man ein Systemabbild erstellen, das im Falle eines Problems den PC wieder auf den Stand…
NEWS | CLOUD COMPUTING | EFFIZIENZ | INFRASTRUKTUR | LÖSUNGEN | OUTSOURCING | RECHENZENTRUM | SERVICES
Das unsichtbare Sicherheitsnetz Cloud-Backup: Backup- und Disaster Recovery

Viele Unternehmen setzen auf eine Kombination verschiedener Backup-Lösungen, häufig über mehrere Standorte hinweg. Im Krisenfall macht es solch eine Strategie jedoch oft schwierig, Dateien zeitnah wiederherzustellen. Dagegen bieten Cloud-integrierte Lösungen einfaches Testen der Disaster-Recovery-Strategie und im Notfall die rasche Rückkehr zum Normalbetrieb. Daten sind für Unternehmen heute wertvolle Rohstoffe und müssen besser gesichert werden als…
NEWS | BUSINESS PROCESS MANAGEMENT | CLOUD COMPUTING | EFFIZIENZ | IT-SECURITY | KOMMENTAR | LÖSUNGEN | SERVICES | STRATEGIEN | TIPPS
Ein gutes Backup muss einfach, sicher und schnell sein

Am 31. März ist der Internationale World Backup Day (https://www.worldbackupday.com/de/ ), der das Verständnis Daten über Backups besser abzusichern stärken soll. Bei der Absicherung von Daten sitzen Verbraucher, KMUs und sogar große Unternehmen im selben Boot: Die Menge der Daten wächst allerorten und die genutzten Technologien werden stetig komplexer. Der World Backup Day hat…
NEWS | DIGITALE TRANSFORMATION | INFRASTRUKTUR | IT-SECURITY | RECHENZENTRUM | SERVICES | AUSGABE 1-2-2018
Modernes Backup & Recovery – Nach der Mauser

Backup & Recovery wird selten in einem Atemzug mit Innovation und digitaler Transformation genannt. Zu Unrecht, denn moderne Ansätze können entscheidend dazu beitragen, aktuelle Herausforderungen im Unternehmen zu meistern und die Produktivität zu steigern. Dazu ist jedoch ein Umdenken in der internen Sicherheitskultur nötig und es muss auf bestimmte Funktionalitäten geachtet werden.
NEWS | BUSINESS PROCESS MANAGEMENT | CLOUD COMPUTING | INFRASTRUKTUR | IT-SECURITY | RECHENZENTRUM | AUSGABE 11-12-2017
Backup-Daten in die Cloud und trotzdem alles unter Kontrolle – Daten sicher in der Wolke

Im Zeitalter der Digitalisierung hängt der Unternehmenserfolg von der ständigen Verfügbarkeit und sicheren Aufbewahrung der Business-relevanten Daten ab. Um diesen Anforderungen gerecht zu werden, treten neue IT-Hersteller mit dem Versprechen am Markt auf, die Verfügbarkeit und sichere Aufbewahrung der Daten gemäß den benötigten Geschäftsanforderungen in einfacher Form umsetzen zu können.
NEWS | BUSINESS | BUSINESS PROCESS MANAGEMENT | CLOUD COMPUTING | INFRASTRUKTUR | IT-SECURITY | ONLINE-ARTIKEL | RECHENZENTRUM | SERVICES | STRATEGIEN | TIPPS
Sechs entscheidende Aspekte für die Neuanschaffung von Backup-Software

Nicht zuletzt das Inkrafttreten der EU-DSGVO als auch die Ransomware-Attacken der vergangenen Monate haben die Bedeutung von Datensicherung verstärkt in den Fokus gerückt. Für viele Unternehmen ist dies ein wichtiger und zugleich komplexer sowie verwirrender Prozess. Das Problem wird durch die Tatsache verschlimmert, dass es Hunderte von verschiedenen Tools gibt, die versprechen, alle Probleme zu…