
Illustration Absmeier foto freepik
Immer mehr Hersteller bezeichnen ihre Systeme als »Parallel File System« – doch nur wenige erfüllen tatsächlich die architektonischen Anforderungen, die dieser Begriff verspricht. Während KI‑ und HPC‑Workloads rasant wachsen, zeigt sich, wie entscheidend echter, direkter Parallelzugriff und eine vollständig vom Datenpfad entkoppelte Metadatenarchitektur für Skalierung und Performance sind. Viele vermeintlich parallele Lösungen bremsen hingegen durch Controller‑Engpässe und serialisierte Metadatenflüsse moderne Datenpipelines spürbar aus. Der Unterschied zwischen Marketing‑Label und echter Parallelität entscheidet damit zunehmend darüber, welche Storage‑Architekturen den Anforderungen hochskalierender KI‑Infrastrukturen wirklich gewachsen sind.
Während KI und beschleunigtes Computing die Datenstrategien von Unternehmen grundlegend verändern, positionieren sich immer mehr Storage-Anbieter mit Architekturen, die sie als »Parallel File Systems« bezeichnen. Leider wird dieser Begriff häufig uneinheitlich verwendet, was für Architekten erhebliche Herausforderungen schafft, wenn sie zwischen Scale-out-NAS, verteilten Object Stores sowie tatsächlichen, echten Parallel-Dateisystemen unterscheiden müssen.
Der Begriff »Parallel File System« entstand in der HPC-Community, zu einer Zeit als parallele Prozessoren massiv die Grenzen von Single-Server Storage offenbarten. Das Konzept entwickelte sich parallel zu MPP- und Hypercube-Architekturen Ende der 1980er- und Anfang der 1990er-Jahre. Forscher suchten damals nach Storage-Architekturen, die mit paralleler Rechenleistung skalieren konnten. Intels Concurrent File System (CFS) demonstrierte bereits entkoppelte Storage-Knoten und gleichzeitigen Zugriff über mehrere I/O-Nodes hinweg, während spätere Forschungssysteme wie IBMs Vesta Storage explizit als parallelen Service und nicht als zentralen Engpass betrachteten. Diese Systeme etablierten ein Grundprinzip, das bis heute gilt: Wenn die Berechnung parallel ist, muss auch der Storage-Zugriff parallel erfolgen.
Was ist ein paralleles Dateisystem?
Über HPC, KI und großskalige Analytik hinweg besteht ein gemeinsames Verständnis dessen, was ein Parallel File System (PFS) ausmacht. Im Kern ist ein PFS eine verteilte Storage-Architektur, in der viele Clients Daten direkt und parallel über mehrere Storage-Knoten hinweg innerhalb eines gemeinsamen Namespace auf Basis von out-of-band bereitgestellten Metadaten zugreifen.
Die Anforderung der direkten Client-zu-Storage Kommunikation ist in diesem Zusammenhang fundamental. In einem echten parallelen Dateisystem kommunizieren Clients nicht über Front-End-Controller, NAS-Heads oder Proxy-Gateways. Stattdessen bauen sie parallele Datenpfade zu vielen Storage-Knoten gleichzeitig auf. Genau das ermöglicht eine lineare und vorhersehbare Skalierung der Performance, wenn zusätzliche Compute- oder Storage-Knoten hinzugefügt werden.
Dieses Prinzip beschränkt sich nicht auf klassische HPC-Systeme, sondern findet sich auch in modernen, standardbasierten Designs wie Parallel NFS (pNFS), einschließlich pNFSv4.2, das in allen gängigen Linux-Distributionen enthalten ist. Bei pNFSv4.2 erhalten Clients beispielsweise Layout-Informationen von einem Metadaten-Server und kommunizieren anschließend direkt mit den entsprechenden Storage-Knoten. Der Metadaten-Server koordiniert Layout-Status und Zugriffsrechte, fungiert jedoch niemals als Datenproxy – ein zentrales Merkmal echter Parallelität.
Metadaten außerhalb des Datenpfads: Das grundlegende Prinzip
Die Trennung von Metadaten und Datenpfad ist vielleicht das wichtigste Merkmal eines parallelen Dateisystems. In einem echten PFS sind Metadaten architektonisch so gestaltet, dass sie keinen serialisierten Engpass darstellen. Stattdessen werden Metadaten-Operationen über mehrere Knoten verteilt, an Clients delegiert und durch intelligentes Caching oder parallele Orchestrierung umgesetzt.
Diese Unterscheidung mag akademisch klingen, hat jedoch tiefgreifende Auswirkungen auf die Performance. In Architekturen, in denen Metadaten- und Datentraffic vermischt sind oder Metadaten-Operationen über Controller-Knoten laufen, ist die Nebenläufigkeit grundlegend eingeschränkt. Moderne PFS-Designs hingegen erlauben es, dass Metadaten unabhängig vom Datenstrom fließen, sodass das System horizontal skalieren kann, ohne dabei Performance einzubüßen. Protokolle wie pNFS verstärken dieses Modell, indem sie Layouts out-of-band bereitstellen, während der Datenfluss vollständig über verteilte, parallele Pfade erfolgt.
Verteiltes Datenlayout und echte Parallelität
Parallele Dateisysteme verteilen Daten über viele Storage-Knoten hinweg so, dass Clients unterschiedliche Teile von Dateien parallel lesen und schreiben können. Ganz gleich, ob dies durch explizites Striping, ausgehandelte Layouts oder aber clientgesteuerte Platzierung erfolgt, das Ergebnis ist identisch: ein System, das für Multi-Node- und Multi-Stream-I/O im großen Maßstab optimiert ist.
Entscheidend ist, dass diese Parallelität aus direktem Zugriff auf mehrere Knoten entsteht und nicht aus der Aggregation von Performance hinter Front-End Controllern, wie es bei Scale-out-NAS Architekturen üblich ist. In einem parallelen Dateisystem ist Skalierbarkeit eine inhärente Eigenschaft des Datenpfades selbst. Das Hinzufügen weiterer Controller zu einem NAS-System kann zwar Kapazität oder Durchsatz bis zu einem gewissen Punkt erhöhen, beseitigt jedoch nicht die architektonischen Einschränkungen von controllervermitteltem I/O.
Echte Skalierbarkeit entsteht durch Clients und Storage-Knoten, nicht durch Controller
Ein weiteres Unterscheidungsmerkmal echter PFS-Architekturen besteht darin, dass die Performance direkt mit der Anzahl der Clients und Storage-Knoten skaliert. Werden zusätzliche GPU-Server und/oder Storage-Knoten hinzugefügt, steigen aggregierter Durchsatz und Nebenläufigkeit auf natürliche Weise.
Architekturen, die I/O über Controller leiten, können diese Art der Skalierung nicht bieten. Unabhängig davon, wie viele Backend-Storage Geräte schlussendlich verwaltet werden, bleiben die Front-End Controller feste Engpässe. In hochgradig parallelen Umgebungen, wie sie moderne KI-Pipelines erfordern, wird diese Einschränkung sehr schnell offensichtlich.
Metadaten-Architektur ist weit wichtiger, als viele Diskussionen vermuten lassen
Die Metadaten-Architektur wird häufig auf vereinfachende Begriffe wie etwa »zentralisiert« oder »verteilt« reduziert. Für effektive KI- und HPC-Performance ist jedoch deutlich mehr Differenzierung erforderlich. In großen Umgebungen müssen Metadaten hohe Nebenläufigkeit unterstützen, Namespace-Operationen parallel bedienen sowie Delegation oder clientseitiges Metadaten-Caching ermöglichen. Für moderne KI-Workloads müssen sie zudem Lokalität über mehrere Standorte und Clouds hinweg bewahren und Metadaten aus externen Storage-Systemen in einen einheitlichen globalen Kontext integrieren.
Diese Fähigkeiten sind entscheidend, da KI-Workloads zunehmend Datensätze umfassen, die über Silos, Protokolle und geografische Regionen verteilt sind. Metadaten müssen global skalieren können, ohne in den Datenpfad einzutreten: ein klarer Vorteil echter paralleler Dateisystem-Architekturen.
Ein globaler Namespace macht ein System noch nicht parallel
Viele Storage-Systeme bewerben heute einen »globalen Namespace«. Dieses Merkmal allein macht ein System jedoch nicht automatisch zu einem parallelen Dateisystem. Ein globaler Namespace bietet einheitliche Sichtbarkeit und Zugriffsmöglichkeiten, garantiert aber keinen parallelen I/O.
Ein paralleles Dateisystem erfordert sowohl einen gemeinsamen Namespace als auch die architektonische Fähigkeit, dass Clients Daten direkt und gleichzeitig über mehrere Storage-Knoten hinweg abrufen können, wobei Metadaten vollständig vom Datenpfad getrennt sind. Einige parallele Dateisysteme bieten diese Fähigkeiten nur innerhalb ihrer eigenen Storage-Domänen, während standardbasierte Ansätze wie pNFS den Metadaten-Layer nutzen, um den Zugriff über heterogene, NFS-basierte Storage-Systeme hinweg zu vereinheitlichen. Diese Unterschiede haben einen erheblichen Einfluss darauf, wie nützlich ein globaler Namespace für KI-Workloads im großen Maßstab wirklich ist.
Multiprotokoll-Unterstützung ist notwendig, aber nicht ausreichend
KI-Workflows erfordern heute häufig sowohl POSIX- als auch S3-Zugriff. Viele Systeme geben an, Datei- und Objektprotokolle zu unterstützen, doch das zugrunde liegende Architekturmodell ist entscheidend. In einigen Designs wird S3-Zugriff über Gateway- oder Controller-Schichten realisiert, wodurch Object-Traffic durch dieselben Engpass-Pfade gezwungen wird wie File-I/O. In anderen Architekturen sind Objekt-Semantiken direkt in die verteilte, parallele Architektur integriert, sodass auch Objektzugriffe horizontal skalieren und denselben Direct-to-Storage Datenpfaden folgen wie Dateizugriffe. Daher reicht es nicht aus, Datei- und Objektprotokolle zu unterstützen, wenn eines davon über zentrale Frontends geleitet wird.
Moderne parallele Dateisysteme haben sich weit über Legacy-Designs hinaus entwickelt
Es ist irreführend, moderne parallele Dateisysteme mit Implementierungen aus den frühen 2000er-Jahren zu vergleichen. Zeitgemäße Designs integrieren verteilte Metadaten-Services, dynamische Layout-Aushandlung, skalierbare und verteilte Locking-Mechanismen, clientseitige Delegation, parallele Namespace-Operationen sowie globale Datenwahrnehmung über mehrere Standorte und Storage-Typen hinweg.
Diese Fähigkeiten spiegeln den Wandel hin zu KI-interaktiven und heterogenen Computing-Umgebungen wider, ganz im Gegensatz zu den Batch-orientierten Workloads, die frühe HPC-Systeme geprägt haben. Der Stand der Technik hat sich erheblich weiterentwickelt.
Controller-Engpässe: die klarste Trennlinie zwischen NAS und PFS
Eine der einfachsten Methoden, Scale-out-NAS von einem parallelen Dateisystem zu unterscheiden, ist die Betrachtung des I/O-Pfads der Clients. Müssen Clients Daten oder Metadaten (unabhängig von der Anzahl der Controller) über Controller-Knoten leiten, wird die Architektur zwangsläufig eine Performance-Obergrenze erreichen, die durch CPU- und Netzwerkkapazität der Controller bestimmt ist.
Diese Einschränkung ist besonders problematisch in KI-Umgebungen, in denen Tausende von GPUs einen erheblichen East-West Traffic erzeugen, Inferenz-Workloads extrem niedrige Latenzen erfordern sowie Metadaten-Operationen parallel bedient werden müssen. Parallele Dateisysteme umgehen diese Grenzen, indem sie Controller aus dem Datenpfad entfernen und direkten, gleichzeitigen Client-Zugriff auf Storage-Knoten ohne Intermediäre ermöglichen.
Rebuild- und Haltbarkeitsfunktionen bieten keinen Differenzierungsvorteil mehr
Viele moderne verteilte Systeme unterstützen fortschrittliches Erasure Coding, parallele Rebuilds sowie flexible Fault-Domain Konfigurationen. Diese Funktionen sind wichtig, aber inzwischen weit verbreitet in Object Stores, Scale-out-NAS und parallelen Dateisystemen. Sie stellen keinen Indikator dar für architektonische Parallelität, sondern spiegeln lediglich den aktuellen Stand von verteilter Storage-Technologie wider.
KI-Workloads gehen weit über Training hinaus (und belasten Storage anders)
Ein Großteil der Diskussionen in der Brache konzentriert sich weiterhin auf Trainings-Benchmarks. Die reale KI-Performance in Unternehmen hängt jedoch zunehmend von Inferenz, Microservices, agentischem KI-Verhalten sowie multimodalen Modellen ab, die schnellen Zugriff auf unterschiedlichste, oft weit verteilte Datentypen benötigen. Diese Workloads zeichnen sich durch hohe Fan-out Muster, extreme Nebenläufigkeit und starke Latenz-Sensitivität aus.
Architekturen, die auf Controller-Knoten oder serialisierte Metadate-Operationen angewiesen sind, geraten unter diesen Bedingungen schnell an ihre Grenzen. Echte parallele Dateisysteme sind für solche Workloads prädestiniert, da sie direkte Zugriffspfade, verteiltes Metadatenmanagement und hohe Nebenläufigkeit ohne zentrale Engpässe bieten.
Was moderne KI-Datenplattformen tatsächlich benötigen
In der Praxis teilen Storage-Systeme, die KI im großen Maßstab unterstützen sollen, eine Reihe gemeinsamer architektonischer Prinzipien. Sie ermöglichen direkte, parallele I/O zwischen Clients und Storage-Knoten, sodass Bandbreite und Nebenläufigkeit mit der Clustergröße skalieren. Sie trennen Metadaten vom Datenpfad und verteilen sie so, dass hohe Parallelität unterstützt wird.
Gleichzeitig bieten solche Systeme einheitliche Semantik für Datei- und Objektzugriff, ohne Gateways in kritische I/O-Pfade einzufügen, sodass mehrere Zugriffsmodelle dieselbe skalierbare Datenebene nutzen können. Sie erstrecken sich über heterogene Storage-Systeme, Clouds und Standorte hinweg, indem sie Metadaten vereinheitlichen, anstatt sie auf eine einzelne physische oder herstellerspezifische Umgebung zu beschränken. Zudem berücksichtigen sie Lokalität innerhalb von GPU-Clustern, sodass der Datenzugriff eng an die Compute-Fabric gekoppelt ist.
Schließlich bevorzugen moderne parallele Architekturen offene, standardbasierte Client-Zugriffe gegenüber proprietären Client-Layern, um breite Kompatibilität und langfristige Flexibilität im großen Maßstab zu gewährleisten.
Zusammengenommen definieren diese architektonischen Eigenschaften sowohl moderne parallele Dateisysteme als auch die Storage-Grundlagen, die erforderlich sind, um Data-Pipelines der künstlichen Intelligenz effektiv zu unterstützen.
Warum echte Parallelität heute wichtiger ist denn je
Ein paralleles Dateisystem ist nicht einfach nur »schnell« oder »scale-out«. Es handelt sich hier um eine Architektur, die durch verteilte Metadaten, direkten und gleichzeitigen Client-Zugriff auf Storage-Knoten sowie die Eliminierung von Controller-Engpässen aus dem Datenpfad definiert wird.
Moderne Implementierungen, einschließlich solcher auf Basis offener Standards wie pNFS, zeigen, wie diese Prinzipien skalierbare Abläufe über heterogene, standortübergreifende und Multi-Cloud Umgebungen hinweg ermöglichen.
Da KI-Infrastrukturen weiter wachsen, sollten Organisationen Technologien anhand dieser architektonischen Grundlagen bewerten und nicht anhand von Labels oder Begriffen aus dem Marketing. Nur Systeme, die auf echter Parallelität basieren, sind schlussendlich in der Lage, die Anforderungen der nächsten Generation von KI-Workloads (Nebenläufigkeit, Durchsatz, Latenz) zu erfüllen.
Floyd Christofferson, Vice President of Product Marketing, Hammerspace
1366 Artikel zu „Storage“
News | Trends 2026 | Cloud Computing | Effizienz | Trends Infrastruktur | Favoriten der Redaktion | Infrastruktur | Infografiken | Rechenzentrum
Storage-Limitierungen bremsen Unternehmen beim Einsatz von KI aus

Für fast alle deutschen IT- und Business-Entscheider ist klar, dass das Training und der Betrieb von KI im eigenen Rechenzentrum viele Vorteile bringt. Zugleich müssen sie aber mehrheitlich einräumen, dass ihre bestehenden Storage-Landschaften dafür ungeeignet sind. Das geht aus der aktuellen »IT Strategy Pulse«-Umfrage von Dell Technologies hervor. Im Rahmen der Umfrage wurden im…
News | Infrastruktur | Rechenzentrum
Pure Storage – eine reale Alternative zu den klassischen Speichergiganten
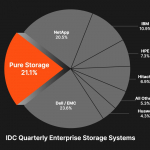
Neben seinem Gründer John Colgrove wird das noch relativ junge Speicher-Unternehmen »Pure Storage« ( »Speicher, nichts als Speicher«) von Charles Giancarlo angefūhrt. Auf der letzten großen Anwenderkonferenz in Las Vegas im Sommer diesen Jahres traten beide nebeneinander als gleichberechtigte Sprecher und Entscheider auf. Colgrove, auch bekannt als »Coz« oder als »Chief Visionary Officer«,…
News | Infrastruktur | Rechenzentrum | Services
Zwischen Datenwachstum und Effizienz: Wie Storage as a Service zur Schlüsseltechnologie wird

Storage: dynamischer Service statt starrer Infrastruktur. Der digitale Wandel zwingt Unternehmen zu einem grundlegenden Umdenken beim Umgang mit ihren Daten. Eine IDC-Studie prognostizierte bereits für dieses Jahr ein weltweites Datenvolumen von rund 175 Zettabyte oder mehr. Laut Statista wird es 2028 auf knapp 400 Zettabyte anwachsen – und sich damit in drei Jahren mehr…
News | TechTalk | Infrastruktur | Künstliche Intelligenz
TechTalk: Darum sollte die Storage-Infrastruktur mit der KI Schritt halten können

Warum spielt die Storage-Infrastruktur im Kontext der Künstlichen Intelligenz eine immer größere Rolle, und welchen Beitrag leistet IBM hierbei? Das wollten wir auf der ISC High Performance 2025 in Hamburg von Robert Haas wissen. Herausgekommen ist dieses knapp 2-minütige Video.
News | Infrastruktur | Produktmeldung | Rechenzentrum
Pure Storage stellt Storage-Produkte der nächsten Generation vor, die Höchstleistung in jeder Größenordnung bieten

Die neuen Pure Storage FlashArray- und FlashBlade-Angebote unterstützen die höchsten Anforderungen für immer intensiver werdende Workloads. Pure Storage, der IT-Pionier, der die weltweit fortschrittlichsten Datenspeichertechnologien und -services anbietet, hat eine Erweiterung seiner Storage-Produkte der nächsten Generation für anspruchsvollste Hochleistungs-Workloads bekannt gegeben. »In einer Zeit, in der Daten an vorderster Stelle stehen und die Komplexität der…
News | Effizienz | Infrastruktur | Rechenzentrum
DAOS und die Höhen und Tiefen von SDS (Software-Defined Storage)

»Distributed Asynchronous Object Storage« (DAOS), von Intel im Jahr 2012 von der kleinen Firma »Whamcloud« übernommen, hat eine wechselvolle Geschichte hinter sich, ohne bis heute zu einem eindeutigen Durchbruch am Speichermarkt für Unternehmen gekommen zu sein. Doch was ist unter »Software-Defined Storage«(SDS) und DAOS genauer zu verstehen? Auf der Web-Seite des Speicherspezialisten »Datacore« finden…
News | Infrastruktur | Lösungen | Rechenzentrum
Die Storage-Spreu vom Weizen trennen: viele Lösungen nicht für Unternehmen geeignet

Der Begriff »Enterprise Class« oder »Unternehmenslösung« sollte Lösungen vorbehalten bleiben, die den strengen Anforderungen großer Organisationen gerecht werden. Einige Anbieter behaupten, dass ihre Produkte für Unternehmen geeignet sind, obwohl sie nur eine Architektur mit doppelter Redundanz anbieten, deren Mängel sie mit Clustering- oder Meshing-Technologien zu kompensieren versuchen. Im Gegensatz zur dreifachen Redundanz können diese Ansätze…
News | Cloud Computing | Infrastruktur | Rechenzentrum | Services
Multicloud-Plattformen für File Storage: Ausweg aus dem Daten-Chaos

Menschen, Anwendungen und Maschinen generieren Daten in nie dagewesener Geschwindigkeit. Die meisten dieser Daten sind unstrukturiert und werden auf File Storage an unterschiedlichen Standorten und in verschiedenen Clouds abgelegt. Für Unternehmen ergeben sich daraus zahlreiche Herausforderungen bei der Verwaltung und Nutzung ihrer Datenschätze. Dell Technologies erklärt, wie Multicloud-Plattformen bei der Bewältigung dieser Herausforderungen helfen. Multicloud-Plattformen…
News | Cloud Computing | Infrastruktur
IT-Perspektiven: Moderne Storage-Ansätze ohne Kompromisse

Ende Januar 2025 fand die von Philippe Nicolas aus Frankreich organisierte IT Press Tour in San Francisco statt. Hartmut Wiehr war für »manage it« vor Ort und schaute sich vier vorgestellte Unternehmen genauer an. Nicht alle jungen Unternehmen in der IT-Branche können sofort einen schnellen Durchbruch verzeichnen. So hat auch »Hammerspace« eine kleine Vorgeschichte:…
News | Business Process Management | Infrastruktur | Rechenzentrum | Services | Strategien
Storage-Management: Warum intelligente Self-Services mittelfristig unverzichtbar sind

Das Storage-Management entwickelt sich schnell weiter. Vorangetrieben durch den KI-Boom und die digitale Transformation müssen Rechenzentren ein massives Datenwachstum, beispiellose Anforderungen an die Agilität von Anwendungen, eine steigende Komplexität, einen Mangel an Fachkräften und steigende Energiekosten bewältigen. Es handelt sich weniger um einen Umbruch als um einen perfekten Sturm, was jedoch auch Chancen für Verbesserungen…
News | Trends 2024 | Digitalisierung | Trends Infrastruktur | Infrastruktur | Rechenzentrum
Der Spagat zwischen Leistung und Effizienz – Technologientrends rund um Storage und Data Management

Markus Grau, Principal Technologist bei Pure Storage, erläutert heute vier Entwicklungen, die seiner Ansicht nach die technologische Entwicklung rund um Storage und Data Management im kommenden Jahr prägen werden. Die Nachfrage nach generativen KI-Lösungen wird eine neue Welle der Container-Einführung auslösen. Der Ansturm auf die Entwicklung und Implementierung generativer KI-Lösungen führt zu einer neuen…
News | Effizienz | Infrastruktur | Künstliche Intelligenz
Large Language Models (LLMs) und Herausforderungen an den Storage – die Bedeutung von Parallelität und Checkpoints

Wenn man die Nachrichten im Bereich Deep Learning verfolgt, hat man sicher zur Kenntnis genommen, dass die Daten und Modelle im Bereich Deep Learning inzwischen sehr groß sind. Die Datensätze können in der Größenordnung von Petabytes liegen, und die Modelle selbst sind ebenfalls Hunderte von Gigabytes groß. Das bedeutet, dass nicht einmal das Modell selbst…
News | Trends 2024 | Trends Infrastruktur | Infrastruktur | Künstliche Intelligenz
Storage-Trends für 2024: Storage, Sexiest Technology Alive?

AI-Daten, mehr Performance für Objektspeicher, besseres Datenmanagement, Datenverwaltung über API und Risk-Management bei der Datenspeicherung werden im kommenden Jahr wichtige Trends. Zugegeben, Data-Storage war noch nie wirklich sexy. Ob auf Band, Festplatte oder Flash, in der Cloud, im Rechenzentrum oder Hybrid, die Datenspeicherung war für die IT immer eher die Pflicht als die Kür.…
News | Cloud Computing | Effizienz | Infrastruktur
Object Storage: »Wir stehen am Anfang einer Welle«

Anwendungsbeispiel des ADN Partners Nugolo. Unternehmen müssen heute große Mengen an Daten speichern, vor Diebstahl oder Verschlüsselung durch Ransomware schützen, über Jahrzehnte revisionssicher aufbewahren und auf Knopfdruck Mitarbeitern, Kunden oder Behörden zur Verfügung stellen können. Diese Anforderungen lassen sich mit herkömmlichen Storage-Ansätzen nicht erfüllen und bedürfen eines kompetenten Partners mit Know-how, wie es der…
News | Cloud Computing | Infrastruktur | Strategien | Ausgabe 9-10-2023
Moderne Storage-Lösungen optimieren die Gesamtperformance, Kosteneffizienz, Nachhaltigkeit und Sicherheit

Ein an die Cloud angebundenes All-Flash-Rechenzentrum senkt die Kosten und kommt der Umwelt zugute, weil es eine bessere Energieeffizienz aufweist. Eine ganzheitliche Managementschnittstelle orchestriert die hybride Multicloud-Infrastruktur und fungiert gleichzeitig als Security-Kontrollzentrale. So kann es durch integrierte Sicherheitslösungen gegen Ransomware-Attacken schützen. Das ist die nächste Welle der Storage-Innovation.
News | Cloud Computing | Infrastruktur | Strategien | Ausgabe 9-10-2023
Der Vierklang: Performance, Skalierbarkeit, Security, Nachhaltigkeit – Highend-Storage im Aufwind

In einer sich ständig wandelnden digitalen Landschaft müssen Unternehmen nicht nur mit der Zeit gehen, sondern vorausdenken. Dabei spielt die effektive Speicherung und Verwaltung von Daten eine entscheidende Rolle. Trotz der zunehmenden Beliebtheit von Cloud-Speicherlösungen bleiben Highend-Speicherarrays im »On-Premises«-Betrieb eine starke Option für Großunternehmen, die eine leistungsfähige, skalierbare und sichere Datenspeicherung benötigen.
News | Infrastruktur | Lösungen
Software-Defined Storage-Lösungen für die Automobilbranche

Große Datenmengen schnell, flexibel und aufwandsarm speichern. Automotive-Unternehmen stehen vor großen Herausforderungen, um im Wettbewerb um die Mobilität der Zukunft mitzuhalten. Diese betreffen nicht nur die Technik im Fahrzeug, sondern auch die Informationstechnologie dahinter und in diesem Zuge vor allem die enormen Datenmengen, die bei der Entwicklung erzeugt und verarbeitet werden. Automotive-Unternehmen brauchen daher…
News | Infrastruktur
Wie die Flut an unstrukturierten Daten die Anforderungen an Storage-Systeme verändert

Menschen, Maschinen und Anwendungen generieren Daten in einem immer höheren Tempo. Der größte Teil der Datenflut ist unstrukturiert und schraubt die Anforderungen an Storage-Systeme deutlich nach oben. Dell Technologies erläutert, was diese leisten müssen, um die wachsenden Datenmengen effizient zu speichern und optimal für die Nutzung bereitzustellen. Unstrukturierte Daten sind Informationen, die sich nicht…
News | Lösungen
SVA macht Cloud Storage zu einfach nutzbaren Services mit Vertrauensbonus

StorageGRID ist das Herz von S3-Objekt-Storage-as-a-Service. Der Komfort von Cloud Storage gewinnt eine persönliche Note. SVA ist einer der führenden Systemintegratoren in Deutschland. Wird Leistung ausgezeichnet, ist SVA häufig unter den Preisträgern. Als SVA hörte, dass Kunden ja zu Cloud Storage aber nein zu Public Clouds sagten, war es Zeit für eine neue Lösung. SVA…
News | Infrastruktur | Services | Strategien
Weniger Stress für IT-Teams: Bereitschaft für neue Nutzungsmodelle auch beim Storage steigt

Die vergangenen Monate waren in vielerlei Hinsicht ein harter Stresstest. Es hat Unternehmen, Arbeitnehmer, Volkswirtschaften und ganze Branchen an ihre Grenzen gebracht. Die kaskadenartigen Auswirkungen der Transformation in eine digitale Welt haben die IT-Infrastrukturen auf eine harte Probe gestellt – und die überlasteten IT-Teams, die sie betreiben, auf eine harte Probe gestellt – und sie…