
Illustration Absmeier foto magnific ki
- Simulation wird zur Plattformfrage: Durch die gleichzeitige Nutzung klassischer HPC‑Simulationen und AI Solver entstehen neue Anforderungen an Architektur, Betrieb und Ressourcensteuerung im Rechenzentrum.
- Ressourcenkonflikte im Tagesbetrieb: Parallel laufende Simulations‑, Trainings‑ und Inferenzjobs konkurrieren um GPUs, Storage und I/O‑Leistung – Engpässe entstehen weniger durch Kapazität als durch fehlende Trennung und Koordination.
- Daten und Scheduling als kritische Faktoren: Hohe Schreiblasten aus Simulationen und zufällige Lesezugriffe aus KI‑Trainings verlagern den Flaschenhals in Storage und Netzwerk; starre Warteschlangen bremsen kurze KI‑Jobs aus.
- Integrierte Steuerung entscheidet über Effizienz: Erst die durchgängige Orchestrierung von Simulation, Training und Inferenz ermöglicht automatisierte Workflows, bessere Ressourcennutzung und eine klare Plattformstrategie.
- KI ergänzt, ersetzt nicht: AI‑Solver liefern Effizienzgewinne innerhalb bekannter Parameterbereiche, erfordern aber kontinuierliche Validierung durch Referenzsimulationen – der Hauptumbruch liegt im Betrieb, nicht im Modell.
Hochleistungsrechner sind seit Jahrzehnten das Rückgrat komplexer Simulationen. Für viele IT-Teams sind sie heute jedoch nicht mehr nur ein wissenschaftliches Werkzeug, sondern ein betrieblicher Engpass – geprägt von steigenden GPU-Anforderungen, wachsendem Energiebedarf und zunehmendem Druck durch zusätzliche KI-Workloads. In der Fusionsforschung, der Astrophysik oder in industriellen CFD-Anwendungen werden physikbasierte Modelle numerisch gelöst, stark parallelisiert und über viele Rechenknoten skaliert. Hohe Genauigkeit geht dabei traditionell mit langen Laufzeiten und entsprechend komplexer Infrastruktur einher.
 Dieses Bild beginnt sich zu verändern. Ergänzend zur klassischen Simulation kommen zunehmend AI Solver zum Einsatz. Dabei handelt es sich um KI-Modelle, die aus bereits berechneten Simulationen lernen und deren Ergebnisse für vergleichbare Fragestellungen direkt nachbilden können. Aufgaben, die früher Stunden oder Tage Rechenzeit benötigten, lassen sich so in Sekunden durchspielen.
Dieses Bild beginnt sich zu verändern. Ergänzend zur klassischen Simulation kommen zunehmend AI Solver zum Einsatz. Dabei handelt es sich um KI-Modelle, die aus bereits berechneten Simulationen lernen und deren Ergebnisse für vergleichbare Fragestellungen direkt nachbilden können. Aufgaben, die früher Stunden oder Tage Rechenzeit benötigten, lassen sich so in Sekunden durchspielen.
Der Druck entsteht dabei nicht nur durch neue Simulationsmethoden, sondern durch die parallele Einführung von KI-Workloads in Umgebungen, die ursprünglich für rein numerische Lasten ausgelegt wurden. Für IT- und Infrastrukturteams bedeutet das: Simulation besteht heute nicht mehr aus einem homogenen HPC-Workload, sondern aus mehreren Rechenarten mit sehr unterschiedlichen Anforderungen. Damit wird Simulation von einer reinen Rechenaufgabe zu einer Plattformfrage – mit direkten Auswirkungen auf Architektur und Betrieb im Rechenzentrum.
Betrieb unter Last
Sobald klassische Simulationen und AI-Solver-Workloads parallel betrieben werden, zeigen sich die Effekte direkt im Tagesbetrieb. In Umgebungen, in denen hochaufgelöste Plasma- oder Teilchensimulationen berechnet werden, belegen einzelne Aufgaben oft mehrere hundert oder tausend GPUs über viele Stunden hinweg. Nach Abschluss eines Laufs werden die erzeugten Felder, Zustandsvektoren oder Strömungsdaten in das parallele Dateisystem geschrieben. Genau diese Datensätze dienen anschließend als Trainingsbasis für KI-Modelle, die beispielsweise Endzustände vorhersagen oder sich an Zwischenwerte für neue Parameterkombinationen annähern.
In der Praxis führt das dazu, dass Trainingsläufe häufig in Zeitfenstern starten, in denen noch große Simulationsjobs laufen. Zwar sind im Rechenzentrum noch GPUs vorhanden, sie können aber nicht genutzt werden, weil sie bereits fest an laufende Simulationsjobs gebunden sind. Umgekehrt kann ein kurzfristig gestarteter Trainingsjob GPUs belegen, die eigentlich für den nächsten Simulationslauf vorgesehen waren. Dieser findet dann nicht mehr genügend zusammenhängende Rechenressourcen und muss warten. Der Engpass entsteht damit nicht durch die Gesamtzahl der GPUs, sondern durch die fehlende Trennung zwischen exklusiv genutzten und flexibel teilbaren Ressourcen.
Ein ähnliches Bild zeigt sich auf der Datenebene. Hochaufgelöste Simulationen erzeugen pro Lauf mehrere Terabyte an Rohdaten, die zunächst sequenziell in das parallele Filesystem geschrieben werden. KI-Trainingsprozesse greifen anschließend wiederholt und parallel auf genau diese Dateien zu, oft in kleineren, zufälligen Zugriffsmustern. In der Praxis bedeutet das, dass ein laufender Checkpoint-Vorgang die Trainingspipelines verlangsamen kann oder umgekehrt ein intensiver Trainingslauf die I/O-Leistung für nachfolgende Simulationen reduziert. Ohne getrennte Pfade für sequenzielle Schreiblast und verteilte Lesezugriffe verschiebt sich der Flaschenhals vom Rechenknoten in das Storage- und Netzwerksystem.
Auch im Scheduling wird der Unterschied sichtbar. Ein typischer Ablauf besteht aus einem langen Simulationslauf, gefolgt von einem Trainingsschritt und mehreren Inferenzläufen, mit denen neue Parameterkombinationen oder Szenarien bewertet werden. Dieser Zyklus wiederholt sich mehrfach am Tag. Wenn alle drei Schritte über dieselbe Warteschlange und dieselben Priorisierungsregeln laufen, kommt es zu Situationen, in denen ein kurzer Inferenzjob hinter einem mehrstündigen Simulationslauf blockiert wird oder ein Trainingsjob den Start eines geplanten Simulationsfensters verzögert.
Der Effizienzgewinn durch AI Solver zeigt sich in diesen Umgebungen nicht auf der Ebene einzelner Jobs, sondern über den gesamten Simulationszyklus. Statt jede neue Parameterkombination numerisch zu berechnen, werden nur ausgewählte Referenzläufe gerechnet und anschließend durch das KI-Modell ergänzt. Der infrastrukturelle Aufwand verlagert sich damit von reiner Rechenzeit hin zu Trainingskapazität, Datenhaltung und kontinuierlichem Betrieb der Modelle.
Steuerung und Plattformstrategie
Auf Systemebene stellt sich damit die Frage, wie der Gesamtworkflow technisch gesteuert wird. In vielen Umgebungen existieren zwei Steuerungsebenen nebeneinander: klassische HPC-Scheduler, die große Simulationsjobs über Warteschlangen und feste Ressourcenblöcke verteilen, und separate Orchestrierungsschichten für KI-Workloads, die Trainingsläufe und Modelle als Services verwalten. Solange beide Ebenen unabhängig arbeiten, bleibt der Simulationszyklus fragmentiert. Erst wenn Training, Inferenz und Referenzrechnung als zusammenhängender Ablauf automatisiert verknüpft werden, lassen sich manuelle Übergaben vermeiden und Ressourcen koordiniert belegen.
Diese Steuerungsebene beeinflusst direkt die Plattformstrategie. Lange, datenintensive Simulationsläufe profitieren von Umgebungen, in denen Rechenleistung und Speicher eng gekoppelt sind. Kurzlebige Trainings- und Inferenzphasen lassen sich dagegen flexibler auf kleineren GPU-Pools oder in hybriden Infrastrukturen betreiben. In der Praxis folgt die Entscheidung dabei weniger einem reinen Kostenvergleich als der Frage, wo sich Daten und Modelle effizienter bewegen lassen. Der Ort der Berechnung wird zunehmend vom Ort der Daten bestimmt, nicht umgekehrt.
Damit diese Entscheidungen im Betrieb nachvollziehbar bleiben, braucht es messbare Steuerungsgrößen, die über klassische Auslastungswerte hinausgehen. Statt nur GPU-Stunden oder Job-Laufzeiten zu erfassen, rücken Kennzahlen wie Energie pro Simulationszyklus, Durchlaufzeit pro Iteration oder die Anzahl belastbarer Ergebnisse pro Trainingslauf in den Fokus. Ergänzt um eine saubere Versionierung von Simulationsdaten und Modellen entsteht so eine technische Grundlage, um Reproduzierbarkeit sicherzustellen und bei Abweichungen gezielt auf frühere Modellstände oder Referenzläufe zurückzugreifen.
Trotz aller Effizienzgewinne haben AI Solver klare Grenzen. Sie liefern belastbare Ergebnisse nur innerhalb des Bereichs, den sie aus bestehenden Simulationen gelernt haben. Ändern sich Randbedingungen, Auflösung oder physikalische Modellannahmen, bleibt die klassische Simulation unverzichtbar. In der Praxis werden KI-Ergebnisse daher regelmäßig gegen neue Referenzläufe geprüft, insbesondere in sicherheits- oder qualitätskritischen Umgebungen.
AI-gestützte Simulationen ersetzen klassische Modelle damit nicht, sondern erweitern sie. Der eigentliche Umbruch findet weniger im Solver als im Betrieb statt. Rechenzentren werden zu Plattformen, die numerische Simulation, Training und produktive Inferenz gleichzeitig tragen, steuern und absichern müssen. Genau an dieser Stelle entscheidet sich, ob der Einsatz von KI in der Simulation zu einem nachhaltigen Effizienzgewinn wird oder zu einer zusätzlichen Komplexität im Betrieb.
Moritz Manthey, Sr. HPC & AI Sales Manager bei Lenovo
270 Artikel zu „HPC“
News | TechTalk | Infrastruktur | Künstliche Intelligenz | Rechenzentrum
TechTalk: So verändern künstliche Intelligenz und HPC die IT-Infrastrukturen der Welt

Welche infrastrukturellen Veränderungen bzw. Anpassungen gehen mit dem Leistungshunger von KI- und HPC-Anwendungen und -Workloads einher, und was leistet Eviden in diesem Kontext? Darüber haben wir uns mit Julien Camiade vom französischen KI-Lösungsanbieter Eviden auf der ISC High Performance 2025 ausgetauscht. Herausgekommen ist dieses Video, in dem Julien unter anderem auf die Green 500-Liste der energieeffizientesten Supercomputer der Welt verweist.
News | Cloud Computing | TechTalk | Infrastruktur | Künstliche Intelligenz | Rechenzentrum
TechTalk: Das verbindet die künstliche Intelligenz mit HPC

Was hat es mit der Verbindung von HPC und der Künstlichen Intelligenz genau auf sich, und wie kommt Amazon Web Services (AWS) dabei ins Spiel? Diese zwei Fragen haben wir auf der ISC High Performance 2025 an Ian Colle gerichtet. Da AWS keinen eigenen Stand auf der Konferenz hatte, haben wir unser Videogespräch im nahegelegenen Park geführt. Das Ergebnis ist dieses gut 2-minütige Interview.
News | TechTalk | Infrastruktur | Rechenzentrum
TechTalk: Darum werden HPC- und KI-Systeme zunehmend mit Warmwasser gekühlt

Auf der ISC High Performance 2025 durften wir mit Ian Lloyd von Supermicro über das Thema Flüssigkeitskühlung sprechen. In diesem Kontext interessierte uns vor allem, warum diese Form der Wärmeableitung eine zunehmend wichtige Rolle spielt und was Supermicro dazu in petto hat. Herausgekommen ist dieses 2-minütige Video, das zeigt, wohin die Reise der Flüssigkeitskühlung geht.
News | Effizienz | Infrastruktur | Rechenzentrum | Strategien
Neuer Ansatz einer Datenspeicherplattform für KI und HPC im großen Maßstab

Für KI-Workloads optimierte All-Flash-basierte Ultra-Scale-Datenspeicherplattformen liefern ausreichenden Speicherdurchsatz und bieten weitreichende Skalierbarkeit. Mit der zunehmenden Verbreitung von KI-Innovationen erkennen viele Unternehmen schnell den Wert, ihre bestehenden Prozesse durch Modelltraining und Inferenz zu verbessern. Dieser Trend hat die Einführung von KI-Workflows in den Bereichen Vorverarbeitung, Training, Test, Feinabstimmung und Bereitstellung vorangetrieben. Alle diese Teilbereiche der…
News | Produktmeldung | Rechenzentrum
Supermicro X14 Max Performance Server für KI, HPC, Virtualisierung und Edge Workloads jetzt verfügbar

Supermicro, ein Anbieter von IT-Gesamtlösungen für KI/ML, HPC, Cloud, Storage und 5G/Edge, beginnt mit der Auslieferung seiner X14 Max Performance Server basierend auf den neuesten Intel Xeon 6900 Prozessoren. Die neuen Systeme bieten Unterstützung für GPUs der nächsten Generation, 400GbE-Netzwerkschnittstellen, E1.S- und E3.S-Laufwerke, MRDIMMs mit hoher Bandbreite von bis zu 8800 MT/s sowie Direct-to-Chip-Flüssigkeitskühlung. Die Supermicro…
News | Produktmeldung | Rechenzentrum
Supermicro präsentiert auf der SuperComputing 2024 das größte Portfolio an HPC-optimierten Multi-Node-Systemen

Komplett neuer FlexTwin™ und neue SuperBlade®-Generation maximieren Rechendichte mit bis zu 36.864 Kernen pro Rack – mit Direct-to-Chip-Flüssigkeitskühlung und verbesserten Technologien zur Maximierung der HPC-Leistung SAN JOSE, Kalifornien und ATLANTA, 20. November 2024 /PRNewswire/ — SuperComputing Conference — Supermicro, Inc. (NASDAQ: SMCI) , ein Anbieter von IT-Gesamtlösungen für KI/ML, HPC, Cloud, Storage und 5G/Edge, stellt…
News | Infrastruktur | Lösungen | Whitepaper
NFS für HPC? DASE-Architektur für das High Performance Computing und künstliche Intelligenz

Im Windschatten der großen Aufmerksamkeit für künstliche Intelligenz (KI) und dem zunehmend ernsthaften Interesse an Quantencomputing erlebt auch das Thema High Performance Computing (HPC) seinen zweiten Frühling. Einer der limitierenden Faktoren war hierbei die Zugriffsgeschwindigkeit auf Speichermedien. Sven Breuner, Field CTO International bei VAST Data, erläutert, wie die DASE-Architektur hier zum Zuge kommt: »Als ich…
News | Produktmeldung
Supermicro beschleunigt die Bereitstellung von HPC-Clustern für IT-Gesamtlösungen
Effiziente Large-Scale-Cluster aus einem Portfolio von über 30 GPU-Systemen und flüssigkeitsgekühlten Standardlösungen, die CPUs mit bis zu 350 Watt und GPUs mit 500 Watt unterstützen. Super Micro Computer, Anbieter von High-Performance-Computing-, Speicher-, Netzwerklösungen und Green-Computing-Technologie, erweitert seine HPC-Marktreichweite für eine Vielzahl von Branchen durch Innovationen auf System- und Clusterebene. Mit seinen IT-Gesamtlösungen kann Supermicro…
News | Veranstaltungen
Learn about the latest Innovations for AI, Data Sience, HPC, Rendering and more

Supermicro’s GTC conference sessions are now available free and on-demand with no GTC pass required. Watch now to learn about Supermicro’s maximum acceleration and cost efficiency for AI, deep learning, and HPC applications.
News | Cloud Computing | Trends Infrastruktur | Digitalisierung | Trends Cloud Computing | Infrastruktur | Trends 2017 | Marketing | Rechenzentrum
K-Computer von Fujitsu auf Platz 1 im HPCG Benchmark-Index
Der K-Computer von Fujitsu hat zum zweiten Mal in Folge den ersten Platz des High Performance Conjugate Gradient (HPCG) Benchmark-Index erreicht. Durch stetiges Verbessern der System- und Anwendungsleistungen hat der Fujitsu K-Computer die Zweitplatzierungen aus den Jahren 2014 und 2015 übertroffen. Für die Benchmark-Auszeichnung wurden alle 82.944 Berechnungsknoten des K-Computer verwendet, um eine Leistung von…
News | Infrastruktur | Produktmeldung | Rechenzentrum
Vertiv baut seine Kompetenzen im Bereich Flüssigkeitskühlungssysteme durch die Übernahme von Strategic Thermal Labs aus

Die Übernahme erweitert das technische Know-how in den Bereichen Cold-Plate-Design, serverseitige Flüssigkeitskühlung und thermische Validierung bei hoher Dichte, um die Leistung, Zuverlässigkeit und die Lebensdauer auf Systemebene zu verbessern. Vertiv, ein weltweit agierender Anbieter für kritische digitale Infrastrukturen, gibt die Übernahme von Strategic Thermal Labs LLC (STL), einem Spezialisten für fortschrittliche Flüssigkeitskühltechnologien, bekannt. Die…
News | Infrastruktur | Kommunikation | Künstliche Intelligenz | Services | Strategien
Das Silicon Valley der 6G-Technologie: Wie Finnland die Ära der kabellosen KI einläutet

6G verbindet Konnektivität mit künstlicher Intelligenz und sensorischen Fähigkeiten. Finnische End-to-End-Kompetenz: Einzigartiges Ökosystem deckt die gesamte Wertschöpfungskette vom Chip bis zur Infrastruktur ab. Chance für deutsche Unternehmen: ideale Testbedingungen und Mitentwicklung zukünftiger Geschäftsmodelle und Standards. Während vielerorts der Fokus auf dem Ausbau von 5G liegt, stellt Finnland bereits die Weichen für die nächste Generation…
News | Effizienz | Favoriten der Redaktion | Infrastruktur | Lösungen | Nachhaltigkeit | Strategien | Tipps
Neues Gebäudemodernisierungsgesetz: Was sich jetzt wirklich lohnt – und was nicht

Regulatorik verschiebt sich – Planungsunsicherheit steigt: Die 65 %-EE-Vorgabe fällt; Eigentümer erhalten mehr Wahlfreiheit, treffen Investitionen aber unter unsicheren politischen Rahmenbedingungen (v. a. Anforderungen ab 2029). Wärmepumpe ist in vielen Fällen heute schon wirtschaftlich: Unter Förderung und erwarteter Preisentwicklung rechnet sich der Umstieg häufig bereits kurzfristig über niedrigere Betriebskosten (typisch 3–5× Effizienz je kWh Strom).…
News | Rechenzentrum | Veranstaltungen
3D‑AI‑Modelle für die Planung und Optimierung von Rechenzentren
Vertiv präsentiert innovative 3D‑AI‑Modelle für die Planung und Optimierung von Rechenzentren auf der Data Centre World Frankfurt 2026 Vertiv, ein weltweit agierender Anbieter für kritische digitale Infrastrukturen, zeigt auf der Data Centre World Frankfurt vom 06. bis 07. Mai 2026 seine neuesten Lösungen für Rechenzentren und KI-Fabriken. Das Unternehmen wird auf der wichtigsten europäischen Rechenzentrumsfachmesse…
News | Effizienz | Infrastruktur | Nachhaltigkeit | Rechenzentrum
Nachhaltigkeit im Rechenzentrum: Zwischen Klimaziel und Kostendruck

Mit der aktuellen Rechenzentrumsstrategie der Bundesregierung rückt neben Investitionen auch das Thema Nachhaltigkeit noch stärker in den Fokus der digitalen Infrastruktur [1]. Für Betreiber und Unternehmen bedeutet das: Neben steigenden Anforderungen entsteht gleichzeitig die Chance, Effizienzpotenziale gezielt zu erschließen und Wettbewerbsvorteile auszubauen. Dabei zahlt sich eine durchdachte Nachhaltigkeitsstrategie auch ökonomisch aus. Sie macht es…
News | Infrastruktur | Rechenzentrum | Services | Tipps
Colocation: So finden Unternehmen die richtige Heimat für ihre Server

Colocation schließt die Lücke zwischen Eigenbetrieb und Cloud: Unternehmen stoßen mit eigenen Serverräumen schnell an Grenzen bei Verfügbarkeit, Sicherheit und Regulatorik. Professionelle Rechenzentren bieten sofort nutzbare, hochverfügbare Infrastrukturen, die intern kaum wirtschaftlich erreichbar wären. Standort & Konnektivität bestimmen Performance und Ausfallsicherheit: Nähe zum Unternehmen, Zugang zu Internetknoten, Carrier‑Neutralität und redundante Netzwege sind zentrale Faktoren für…
News | Infrastruktur | Rechenzentrum
AI in der Hitzefalle? Friedrich Merz informiert sich über AI, Rechenzentren, Wettbewerbsfähigkeit

Beim Besuch auf der Hannover Messe informierte sich Bundeskanzler Friedrich Merz bei Rittal und Eplan über AI, Rechenzentren und die Stärkung der Wettbewerbsfähigkeit der Industrie. AI-Anwendungen erhöhen den Bedarf an neuen Rechenzentren mit moderner IT-Infrastruktur deutlich; Rittal liefert bereits in großem Maßstab (u. a. 180.000 Server-Racks/Jahr) an große Cloudanbieter. Die Bundesregierung verfolgt eine ehrgeizige Rechenzentrumsstrategie:…
News | IT-Security | Künstliche Intelligenz | Rechenzentrum | Strategien
Quantenbedrohung: Warum Unternehmen heute handeln müssen

Post-Quantum-Kryptografie wird zur strategischen Pflicht – nicht zur Zukunftsoption. Noch existieren leistungsfähige Quantencomputer nur in Forschungsumgebungen – doch die Bedrohung ist längst real. Angreifer speichern bereits heute verschlüsselte Daten, um sie später zu entschlüsseln. Warum Unternehmen jetzt handeln müssen, welche technischen und regulatorischen Faktoren beachtet werden müssen und wie eine praktikable Migration aussieht, erklärt…
News | Effizienz | Favoriten der Redaktion | Infrastruktur | Nachhaltigkeit | Rechenzentrum
Nachhaltige Datenarchitekturen: Wie effizientes Systemdesign Kosten und CO2 reduziert

Deutschland baut seine digitale Infrastruktur immer weiter aus. Neue Einrichtungen wie das KI-Zentrum in München sollen riesige und ständig wachsende Datenmengen verarbeiten. Mehr Daten erfordern mehr Speicherplatz, mehr Rechenleistung und mehr Systeme, die rund um die Uhr im Einsatz sind. Damit rückt das Thema Nachhaltigkeit immer dringlicher in den Fokus. Der Energieverbrauch in Dateninfrastrukturen…
Trends 2026 | News | Trends 2030 | Trends Infrastruktur | Effizienz | Infrastruktur | Infografiken
Verbrauch von Erdgas sinkt mittelfristig nur in Europa
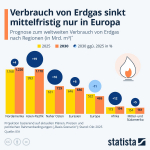
Erdgas gilt in der Energiewende als Brückentechnologie, da es weniger CO₂-Emissionen verursacht als andere fossile Energieträger wie etwa Kohle oder Öl. Zugleich verursacht Erdgas nach Kohle, Torf und Ölschiefer weltweit die meisten CO₂-Emissionen bei der Strom- und Wärmeerzeugung. Wie wird sich der Verbrauch dieses ambivalenten Rohstoffs in den nächsten Jahren entwickeln? Die International Energy Agency…