

foto freepik ki
Abstract
Die englischsprachige Wikipedia hat den Einsatz großer Sprachmodelle (LLMs) zum Generieren oder Umschreiben von Artikelinhalt untersagt und nur eng begrenzte Ausnahmen für Copyediting eigener Texte sowie Übersetzungsunterstützung zugelassen. Diese Entscheidung lässt sich nicht allein als redaktionelles Qualitätsinstrument verstehen, sondern als datenökologischer Eingriff in ein globales Trainingsdaten‑Ökosystem, das zunehmend durch synthetische Inhalte geprägt wird. Zentraler technischer Bezugspunkt ist das in der Literatur breit diskutierte Phänomen des Model Collapse beziehungsweise der AI autophagy: Werden generative Modelle rekursiv mit modellgenerierten Daten trainiert, verengen sich Ausgabeverteilungen, Randfälle verschwinden, und Fehler beziehungsweise Verzerrungen können sich über Generationen verstärken.
Einleitung
Mit dem im März 2026 nach einem Request‑for‑Comment (RfC) beschlossenen Verbot, LLMs zum »generating or rewriting article content« einzusetzen, positioniert sich Wikipedia als eine der ersten großen Wissensinfrastrukturen, die generative Textproduktion in Kerninhalten explizit begrenzt. In den begleitenden Begründungen werden neben klassischen Wikipedia‑Normen (Verifizierbarkeit, Bedeutungsverschiebungen durch »polishing« etc.) insbesondere der Aufwand der menschlichen Qualitätssicherung sowie die Gefahr überzeugend wirkender, aber nicht quellengedeckter Veränderungen hervorgehoben. Darüber hinaus weist die Debatte auf eine systemische Ebene: Wikipedia ist eine zentrale Referenzressource und zugleich ein häufig genutzter Bestandteil großskaliger Web‑Korpora, die zum Training nachfolgender Modelle herangezogen werden. Die Wikipedia‑Entscheidung adressiert damit ein Problem, das in der Forschung nicht primär als »Content Moderation«, sondern als Stabilitätsfrage rekursiver Trainingsprozesse behandelt wird.
Theoretischer Hintergrund: Rekursives Training und Verteilungsverengung
Unter Model Collapse wird in der Nature‑Arbeit von Shumailov et al. (2024) ein degenerativer Prozess verstanden, bei dem modellgenerierte Daten schrittweise den Trainingssatz nachfolgender Generationen »polluten«, wodurch Modelle »reality mis-perceive« und insbesondere die »tails of the original content distribution« verschwinden. Die Autoren unterscheiden explizit early model collapse (Verlust seltener Ereignisse bzw. Verteilungsränder) und late model collapse (Konvergenz auf eine Verteilung mit deutlich reduzierter Varianz und geringer Ähnlichkeit zur Ausgangsverteilung). Wichtig ist dabei die Generalität der Beobachtung: Der Effekt wird nicht nur für LLM‑Settings diskutiert, sondern auch für Variational Autoencoders (VAEs) und Gaussian Mixture Models (GMMs) demonstriert. Methodisch begründen Shumailov et al. den Kollaps als Ergebnis über Generationen kumulierender Fehlerquellen (u. a. endliche Stichproben/»finite sampling« sowie Approximations‑/Expressivitätsgrenzen) und zeigen, dass Verteilungsränder bei rekursivem Sampling besonders anfällig sind.
Eine komplementäre Perspektive liefert das arXiv‑Preprint von Alemohammad et al. (2023), das den Prozess als Model Autophagy Disorder (MAD) rahmt: In »self‑consuming« Trainingsschleifen nimmt ohne hinreichenden Zufluss frischer Real‑Daten über Generationen entweder Qualität/Präzision oder Diversität/Recall progressiv ab. Die Autoren analysieren dazu mehrere Familien autophagischer Trainingsregime und betonen, dass das Problem nicht durch bloße Verfügbarkeit synthetischer Daten gelöst wird, sondern durch die Stabilität der Schleife und die Rolle realer Datenanteile in jeder Generation. Diese Befunde werden im Übersichtsbeitrag »On the caveats of AI autophagy« (Xing et al., 2025) in einen breiteren Kontext eingeordnet: Die vormals kontrollierte Mischung realer und synthetischer Daten werde durch unregulierte Verbreitung synthetischer Inhalte online zunehmend unkontrollierbar; Web‑Scraping‑Korpora würden damit strukturell kontaminiert, was Zuverlässigkeit und Performance generativer Systeme langfristig beeinträchtigen könne.
Modalitätsspezifische Manifestationen: Texte vs. Bilder
Obwohl das Grundprinzip – rekursives Lernen aus geglätteten, modelltypischen Samples – modalitätsübergreifend gilt, unterscheidet sich die Erscheinungsform in Text‑ und Bilddomänen. Für Textmodelle beschreibt die Literatur insbesondere den Verlust von Verteilungsrändern (rare tokens, seltene Konstruktionen, Nischenmuster) als frühen Indikator; dies folgt direkt aus dem von Shumailov et al. hervorgehobenen Mechanismus des »tail disappearance«. Praktisch äußert sich dieser Verlust als sinkende stilistische und semantische Bandbreite, während Oberflächenfluency zunächst erhalten bleiben kann – ein Umstand, der in Debatten um Wikipedia besonders relevant ist, weil enzyklopädischer Stil für LLMs gut imitierbar ist und Qualitätsprobleme erst bei Quellenbindung und Bedeutungspräzision sichtbar werden. Für Bildmodelle betont die MAD‑Arbeit die empirische Tendenz, dass autophagische Schleifen zu einem Trade‑off zwischen wahrgenommener Qualität und Vielfalt führen; ohne frische Real‑Daten wird entweder die Diversität reduziert oder es entstehen Artefakt‑/Modellfingerprint‑Verstärkungen über Generationen. Xing et al. (2025) rahmen beide Modalitäten unter dem gemeinsamen Risiko unmarkierter synthetischer Kontamination, wobei der entscheidende Punkt nicht »Synthetik« per se ist, sondern deren unkontrollierte Akkumulation in den Datenpipelines großskaliger Modelle.
Wikipedia als datenökologischer Eingriff: Schutz einer Trainingsdaten‑Keystone‑Ressource
Vor diesem Forschungshintergrund kann die Wikipedia‑Entscheidung als Präventionsmaßnahme gegen rekursive Kontaminationsschleifen gelesen werden. MediaNama berichtet, dass der RfC mit 44:2 Stimmen geschlossen wurde und der Beschluss zwei enge Ausnahmen vorsieht: Copyedits (an eigenem Text) und eine erste Übersetzungsfassung, jeweils mit menschlicher Prüfung. TechCrunch zitiert die neue Richtlinienformulierung, wonach »the use of LLMs to generate or rewrite article content is prohibited«, erlaubt aber LLM‑Unterstützung beim Copyediting eigener Texte nach menschlichem Review – bei explizitem Hinweis, dass LLMs die Bedeutung in nicht quellengedeckter Weise verändern können. Genau diese Bedeutungsverschiebung ist aus Sicht der Verteilungslogik plausibel: Wenn Modelle auf »wahrscheinliche« Formulierungen optimieren, tendieren sie zu Glättung, Generalisierung und plausibler Rekombination; die semantischen Ränder (Ausnahmen, sorgfältig abgegrenzte Behauptungen, minoritäre Perspektiven) sind besonders verletzlich.
Entscheidend ist zudem die Rolle Wikipedias als hochgradig wiederverwendete Quelle: Wikipedia‑Inhalte werden – so die berichtete Begründungslogik – in großem Umfang als Trainingsmaterial oder als Bestandteil webbasierter Korpora genutzt, wodurch KI‑generierte Wikipedia‑Artikeltexte ein »compounding risk« erzeugen: Unzutreffende oder halluzinierte Textteile könnten in künftige Trainingsdaten zurückfließen. Damit adressiert Wikipedia nicht nur lokale Qualitätskosten (Verifikation dauert länger als Generierung, Belastung der Freiwilligen), sondern potenziell einen systemischen Effekt, den Shumailov et al. als generationalen Drift weg von der ursprünglichen Datenverteilung beschreiben. In diesem Sinne ist das Verbot weniger eine Absage an KI‑Werkzeuge als ein Versuch, eine »Keystone‑Ressource« der Wissens‑ und Dateninfrastruktur vor synthetischer Drift zu schützen – eine Perspektive, die explizit als »Datenökologie« und Rückkopplungsproblem formuliert wird.
Implikationen und Gegenmaßnahmen (aus der Literatur abgeleitet)
Die wissenschaftliche Literatur ist in einem Punkt bemerkenswert konsistent: Stabilität rekursiver Trainingsschleifen erfordert den fortlaufenden Zugriff auf Real‑Daten beziehungsweise auf Mechanismen, die verhindern, dass synthetische Datenanteile unmarkiert und unkontrolliert dominieren. Shumailov et al. betonen, dass das Verschwinden der Tails und die Varianzreduktion über Generationen selbst unter idealisierten Bedingungen auftreten können und dass der Zugriff auf die ursprüngliche Datenverteilung (bzw. auf genuin menschlich erzeugte Daten) für Aufgaben zentral ist, in denen Randfälle relevant sind. Xing et al. (2025) diskutieren das Problem als Governance‑ und Pipeline‑Frage: Sobald synthetische Inhalte breit online zirkulieren und nicht zuverlässig gekennzeichnet sind, wird selbst gut gemeintes Web‑Scraping zur Vermischung von Real‑ und Modelloutputs, wodurch »strategic balance« und Provenienzarbeit entscheidend werden. Aus dieser Perspektive ist Wikipedias Regelung kompatibel mit einem »Provenienz‑First«‑Ansatz: Sie erlaubt KI dort, wo sie nicht als primäre Inhaltsquelle fungiert (sprachliches Glätten eigener Texte; Übersetzung als Assistenz), insistiert aber auf menschlicher Verantwortung und Quellenbindung, um synthetische Dominanz im Korpus zu vermeiden.
Fazit
Die Wikipedia‑Entscheidung lässt sich als frühes institutionelles Signal lesen, dass die Nachhaltigkeit generativer KI nicht ausschließlich von Modellarchitektur und Rechenleistung abhängt, sondern wesentlich von der Qualität, Provenienz und Diversität der Trainingsdaten. In der Terminologie der Forschung adressiert Wikipedia damit indirekt das Risiko von Model Collapse beziehungsweise AI autophagy: rekursives Training auf modellgenerierten Daten verengt Verteilungen, eliminiert Tails und kann Fehler kumulativ verstärken. Die in der Richtlinie erlaubten Ausnahmen (Copyediting/Übersetzung mit menschlicher Prüfung) sind aus datenökologischer Sicht konsequent, weil sie KI als Werkzeug zur Bearbeitung menschlicher Primärtexte zulassen, nicht aber als Quelle neuer enzyklopädischer Behauptungen. Damit wird Wikipedia zu einem Fallbeispiel dafür, wie Wissensinfrastrukturen durch Governance‑Entscheidungen aktiv in die Stabilität zukünftiger KI‑Trainingsökosysteme eingreifen können – nicht als Technikverbot, sondern als Schutzmaßnahme gegen systemische Daten‑Rückkopplungen.
Albert Absmeier & KI
Quellen
-
Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., & Gal, Y. (2024). AI models collapse when trained on recursively generated data. Nature, 631, 755–759. https://doi.org/10.1038/s41586-024-07566-y [nature.com]
-
Alemohammad, S., Casco-Rodriguez, J., Luzi, L., Humayun, A. I., Babaei, H., LeJeune, D., Siahkoohi, A., & Baraniuk, R. G. (2023). Self-Consuming Generative Models Go MAD. arXiv preprint arXiv:2307.01850. https://doi.org/10.48550/arXiv.2307.01850 [arxiv.org]
-
Xing, X., Shi, F., Huang, J., Wu, Y., Nan, Y., Zhang, S., Fang, Y., Roberts, M., Schönlieb, C.-B., Del Ser, J., & Yang, G. (2025). On the caveats of AI autophagy. Nature Machine Intelligence, 7, 172–180. https://doi.org/10.1038/s42256-025-00984-1 [nature.com]
-
Ropek, L. (2026). Wikipedia cracks down on the use of AI in article writing. TechCrunch (26 March 2026). [techcrunch.com]
-
Bansal, A. (2026). Wikipedia bans AI-generated article content after RfC. MediaNama (26 March 2026). [medianama.com]
4898 Artikel zu „KI Risiko“
News | Business | Digitalisierung | Favoriten der Redaktion | Kommentar | Künstliche Intelligenz | Strategien | Tipps
Warum Wikipedia den Einsatz generativer KI einschränkt: Habsburg KI als datenökologisches Risiko

Die Entscheidung der englischsprachigen Wikipedia, den Einsatz großer Sprachmodelle (Large Language Models, LLMs) zum Schreiben oder Umschreiben von Artikeln weitgehend zu untersagen, markiert einen Wendepunkt im gesellschaftlichen Umgang mit generativer künstlicher Intelligenz. Auf den ersten Blick wirkt das Verbot paradox: Gerade LLMs sind in der Lage, formal korrekte, gut strukturierte und enzyklopädisch anmutende Texte zu…
News | Trends 2026 | Business | Trends Security | Favoriten der Redaktion | Geschäftsprozesse | IT-Security | Künstliche Intelligenz
Unternehmensrisiko: KI im Einsatz ohne Kontrolle

Die meisten Unternehmen können nicht sagen, wie schnell sie ein KI-System in einer Krise stoppen könnten – und viele könnten danach nicht erklären, was schiefgelaufen ist. KI-Technologie wird in europäischen Unternehmen in rasantem Tempo eingeführt, aber viele haben sie ohne die passende Governance- und Sicherheitsinfrastruktur implementiert. Das geht aus einer neuen Studie von ISACA…
News | Favoriten der Redaktion | IT-Security | Künstliche Intelligenz | New Work
Agents of Chaos: KI-Agenten als neue Risikoklasse

Autonome KI‑Agenten auf Basis von Large Language Models (LLMs) entwickeln sich rasant von experimentellen Chatbots zu handlungsfähigen Systemen, die eigenständig Aufgaben ausführen, Werkzeuge nutzen, kommunizieren und Entscheidungen treffen. Das Paper »Agents of Chaos« analysiert erstmals systematisch, welche neuen Sicherheits‑, Datenschutz‑ und Governance‑Risiken dadurch entstehen [1]. Die Studie basiert auf einer zweiwöchigen Red‑Teaming‑Untersuchung mit realistisch…
News | Trends 2026 | Business | Trends Wirtschaft | Geschäftsprozesse | Künstliche Intelligenz | Nachhaltigkeit | New Work | Strategien
Mehr Risikokapital für KI – weniger für Energie

Laut Internationaler Energieagentur konkurrieren Energie‑Startups immer stärker mit KI‑Firmen um Risikokapital (Venture Capital, VC) [1]. Der KI‑Boom verschiebe Kapital und Aufmerksamkeit – auch von großen generalistischen Fonds – in Richtung KI. Die IEA weißt zugleich daraufhin, dass der Rückgang energiebezogener VC‑Finanzierung auch mit dem Auslaufen eines großen Finanzierungszyklus in der Elektromobilität (EVs und EV‑Batterien) zusammenhängt.…
News | Business | IT-Security | Ausgabe 11-12-2025 | Security Spezial 11-12-2025
Welche Compliance-Risiken beschert KI deutschen Unternehmen – Vom Regelhüter zum Risikonavigator

Das Interview mit Oliver Riehl, Regional Vice President DACH bei NAVEX, beleuchtet die Herausforderungen und Chancen, die künstliche Intelligenz (KI) für deutsche Unternehmen im Bereich Compliance mit sich bringt. Riehl betont, dass KI helfen kann, Ordnung in die wachsende Komplexität der Regularien zu bringen, jedoch eine gute Governance und klare Richtlinien erforderlich sind, um effektiv eingesetzt zu werden. Zudem wird die Bedeutung einer vertrauensvollen Compliance-Kultur hervorgehoben, um Datenverluste zu vermeiden und die Effizienz von Hinweisgebersystemen zu steigern.
News | Effizienz | Geschäftsprozesse | IT-Security | Künstliche Intelligenz | Tipps
Prüfbare KI-Qualität: MISSION KI präsentiert Qualitätsstandard und digitales Prüfportal für Niedrigrisiko-KI

Der VDE hat sich an dem Projekt MISSION KI – Nationale Initiative für Künstliche Intelligenz und Datenökonomie beteiligt. Entstanden sind ein Qualitätsstandard und ein Portal für die strukturierte Bewertung der Qualität von KI-Systemen, die sich unterhalb der Hochrisikoschwelle befinden. Die Partner des Projekts MISSION KI – Nationale Initiative für Künstliche Intelligenz und Datenökonomie haben…
News | Trends Security | IT-Security | Künstliche Intelligenz
Cybervorfälle sind das größte Geschäftsrisiko – KI in diesem Zusammenhang Fluch und Segen zugleich

Cyberangriffe sind in Deutschland das größte Geschäftsrisiko – noch vor Naturkatastrophen, politischen Risiken oder regulatorischen Herausforderungen. Das zeigt die aktuelle Umfrage Allianz Risk Barometer 2025. Jüngste Vorfälle zeigen: Bedrohung ist real Allein im Juli 2025 sorgten zahlreiche Bedrohungen für Schlagzeilen. Darunter sogenannte DDoS-Attacken auf kommunale Websites von Stadtverwaltungen, S-Bahnen und Landratsämtern. Solche Angriffe verfolgen das…
News | Business | Favoriten der Redaktion | Künstliche Intelligenz | Strategien | Tipps
KI ohne wirksames Risikomanagement ist verantwortungslos

Globale Technologien und lokale Gesetze erfordern verantwortungsvollen Umgang mit KI. Die Entwicklung von künstlicher Intelligenz schreitet weiter voran, doch weltweit fehlt es an einheitlichen Vorgaben. Während die EU mit dem AI Act und der Datenschutzgrundverordnung (DSGVO) zwei rechtlich verbindliche Regelwerke geschaffen hat, gibt es international viele Lücken. Für global tätige Unternehmen bedeutet das vor…
News | Cloud Computing | IT-Security | Künstliche Intelligenz | Ausgabe 5-6-2025
KI zwingt Unternehmen, Abstriche in Sachen Hybrid-Cloud-Sicherheit zu machen – Public Cloud als größtes Risiko

KI verursacht größeres Netzwerkdatenvolumen und -komplexität und folglich auch das Risiko. Zudem gefährden Kompromisse die Sicherheit der hybriden Cloud-Infrastruktur, weshalb deutsche Sicherheits- und IT-Entscheider ihre Strategie überdenken und sich zunehmend von der Public Cloud entfernen. Gleichzeitig gewinnt die Netzwerksichtbarkeit weiter an Bedeutung.
IT-Security | Ausgabe 11-12-2024 | Security Spezial 11-12-2024
it-sa 2024: Zwischen KI-gestützter Bedrohungsabwehr und digitaler Identität – Von reaktiver Gefahrenabwehr zu proaktivem Risikomanagement

Die Messehallen in Nürnberg verwandelten sich auch 2024 wieder zum Epizentrum der IT-Sicherheitsbranche. Die it-sa bestätigte einmal mehr ihre Position als Europas führende Fachmesse für Cybersecurity. Die Rekordbeteiligung internationaler Aussteller unterstrich dabei den Stellenwert der Veranstaltung weit über den deutschsprachigen Raum hinaus. Während die Gänge von geschäftigem Treiben erfüllt waren, kristallisierten sich rasch die dominierenden Themen heraus: Der Umgang mit künstlicher Intelligenz, die Bedeutung digitaler Identitäten und die wachsende Verschmelzung von IT- und OT-Security.
News | Trends 2024 | Trends Security | IT-Security | Künstliche Intelligenz
71 Prozent der Verbraucher sieht KI als Risiko für Datensicherheit

Große Mehrheit der Endkunden prüft Wechsel zur Konkurrenz, wenn Anbieter ihre Daten nicht wirksam schützen. Weltweit sind Verbraucher sehr besorgt über die Menge an Daten, die Unternehmen über sie sammeln, den Umgang damit und sehen auch deren Sicherheit gefährdet – insbesondere durch die den zunehmenden Einsatz von künstlicher Intelligenz. Das belegt eine Umfrage von…
News | Business Process Management | Digitalisierung | Geschäftsprozesse | Services
Risikomanagement: KI-gestützte Risikoanalyse

Mit KI-gestützten Projektmanagement-Anwendungen schneller, flexibler und sicher zum Erfolg. Mit auf KI- und maschinellem Lernen (ML)-gestützten Datenanalysetools können Unternehmen ihr gesamtes Projektportfolio scannen und die risikoreichsten Projekte und Arbeitspakete identifizieren. Außerdem lassen sich auf Projektbasis Simulationen durchführen und wahrscheinliche Risiken aufzeigen, die bei einer manuellen Analyse möglicherweise nicht erkennbar sind. Monte-Carlo-Analyse (Szenarioanalyse) Die…
News | Business | Trends 2024 | Künstliche Intelligenz
Deutschland zu risikoscheu bei Nutzung und Einsatz von KI

Verbraucher erkennen die Vorteile von KI für Wirtschaft und Gesellschaft. Bedenken vor allem in Bezug auf Cybersicherheit. Nach dem »Jahr der künstlichen Intelligenz (KI)« hat eine aktuelle, repräsentative Umfrage von Splunk, Anbieter in den Bereichen Cybersicherheit und Observability, ein gemischtes, aber weitgehend positives Bild der öffentlichen Einstellung zur KI aufgezeigt. Die Mehrheit der Befragten…
News | IT-Security | Produktmeldung
Mobile Sicherheit und Risikomanagement: Wettbewerbsanalyse und Ranking der führenden Anbieter für In-App-Schutzlösungen
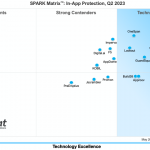
In einer neuen Marktstudie hat das Analystenhaus Quadrant Knowledge Solutions die Stärken und Schwächen von In-App-Schutzlösungen untersucht. Neben einer Wettbewerbsanalyse umfasst die Untersuchung ein Ranking der führenden Technologieanbieter. Die »Quadrant Knowledge Solutions SPARK Matrix« beinhaltet eine detaillierte Analyse der globalen Marktdynamik, der wichtigsten Trends, der Anbieterlandschaft und Wettbewerbsposition. Darüber hinaus bietet die Studie strategische Informationen,…
News | Business | Trends Wirtschaft | Digitalisierung | Trends Kommunikation | Trends 2018 | Services
Künstliche Intelligenz: Bürger sehen mehr Risiko als Nutzen in KI
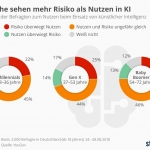
Künstliche Intelligenz wird unsere Gesellschaft grundlegend verändern, das steht fest. Ob diese Veränderungen positiv oder negativ sein werden, darüber sind sich die Deutschen nicht einig, wie eine Umfrage von YouGov zeigt. Während 15 Prozent aller Befragten glauben, der Nutzen von KI sei größer als das Risiko, denken immerhin 26 Prozent das Gegenteil. Beinahe die Hälfte…
News | Business Process Management | Effizienz | Favoriten der Redaktion | Geschäftsprozesse | Künstliche Intelligenz | Strategien | Tipps
KI beginnt mit Vertrauen: Daten-Governance als Schlüssel zwischen Strategie und messbaren Resultaten

Der Erfolg von KI hängt weniger von Modellen als von vertrauenswürdigen, geschäftlich nutzbaren Daten ab, weshalb viele Initiativen an fehlender Daten‑Governance scheitern. Moderne Daten‑Governance wird dabei als Enabler verstanden, der Klarheit, Verantwortlichkeiten und Datenqualität schafft und KI so skalierbar und wirksam macht. Entscheidend ist ein dynamischer Data‑First‑Ansatz, der Governance als kontinuierliches Change Management etabliert und…
News | Trends 2026 | Trends Security | Favoriten der Redaktion | IT-Security | Künstliche Intelligenz | New Work
70 Prozent der Unternehmen genehmigen KI-Projekte trotz Sicherheitsbedenken

Jeder sechste Entscheider in Deutschland stuft Besorgnis als »extrem« ein – und wurde dennoch zugunsten von Wettbewerbsdruck und internen Forderungen übergangen. TrendAI, ein Geschäftsbereich von Trend Micro und Anbieter von KI-Sicherheit, veröffentlicht neue Forschungsergebnisse, die zeigen, dass Unternehmen weltweit den Einsatz von künstlicher Intelligenz vorantreiben, obwohl bekannte Sicherheits- und Compliance-Risiken bestehen [1]. Eine neue…
News | Business | Künstliche Intelligenz | Lösungen | New Work | Produktmeldung
Business-KI: Amazon Quick bringt agentische KI in den DACH-Raum

Amazon Quick jetzt in der AWS Region Europa (Frankfurt) verfügbar. KI hat sich im Alltag längst als selbstverständlicher Helfer etabliert. In Unternehmen sieht die Realität allerdings oft anders aus. Genau hier unterstützt die agentische KI-Anwendung Amazon Quick von AWS. Sie hilft bei Recherchen, Business-Intelligence-Analysen und der Automatisierung von Workflows. Ab sofort können Unternehmen in…
News | Effizienz | Geschäftsprozesse | Kommunikation | Künstliche Intelligenz | New Work | Produktmeldung
Island ermöglicht sicheren und vertraulichen Einsatz von KI in Unternehmen

Neuer KI-Browser, Sicherheitsfunktionen, Agentensteuerung und Publishing ermöglichen den Einsatz von KI im großen Maßstab. Island, das Unternehmen für Enterprise-Workspace, stellt neue KI-Lösungen für den sicheren Einsatz in Unternehmensumgebungen vor. Sie helfen Organisationen, künstliche Intelligenz sicher einzuführen und zu skalieren. Während generative KI, KI-Browser und autonome Agenten zunehmend den Arbeitsalltag prägen, liefert Island das, was…
News | Trends 2026 | Business | Business Process Management | Favoriten der Redaktion | Geschäftsprozesse | Trends Geschäftsprozesse | Künstliche Intelligenz | Whitepaper
Massive Dynamik hin zum KI‑gestützten Prozessmanagement

Künstliche Intelligenz entwickelt sich im Prozessmanagement vom Analyse‑Werkzeug zum aktiven Gestalter und läutet das Zeitalter des »Agentic BPM« ein. Immer mehr Unternehmen setzen bereits auf generative KI und KI‑Agenten, doch strategische Nutzung, Governance und Datenqualität bremsen oft die Skalierung. Wer jetzt gezielt in Entscheidungsintelligenz, Kompetenzen und saubere Prozessarchitekturen investiert, verschafft sich nachhaltige Effizienz‑ und Innovationsvorteile.…