Die richtige Data Preparation erhöht die Vorhersagequalität von Datenmodellen und steigert die Wirksamkeit von Machine Learning-Zyklen.
Die meisten Daten sind ohne eine vorher durchgeführte Data Preparation für KI-gestützte Prognosen ungeeignet: ihre Qualität ist unzureichend, sie liegen nicht in numerischer Form vor, oder es fehlen Werte. Diese Handlungsempfehlungen unterstützen bei der Datenvorbereitung und helfen, den Aufwand dafür nicht nur beträchtlich zu reduzieren, sondern auch die Qualität der Vorhersagen Ihres Predictive-Analytics-Modells signifikant zu verbessern. Die 4 Schritte können auch als Whitepaper mit kompletter Anleitung heruntergeladen werden [1].
Die Data-Preparation-Phase besteht aus vier Teilschritten: Data Exploration, Feature Cleansing, Feature Engineering und Feature Selection. Für jede dieser Prozessstufen gibt es Optimierungsmöglichkeiten, mit denen Sie die Datenvorbereitung sowohl effektiver als auch effizienter gestalten können.
- Data Exploration
In der Explorationsphase entwickeln Sie ein grundlegendes Verständnis für die Daten. Mit statistischen Analyseverfahren beschreiben Sie die Merkmale (Features), etwa indem Sie Minima und Maxima, die Lagemaße und die Datenverteilung sowie Zusammenhangmaße ermitteln.
Weiterhin bestimmen Sie die Datenqualität und decken dabei insbesondere Qualitätsdefizite auf, die Sie in den nächsten Schritten beheben werden. Dazu gehören
- fehlende Daten: Die meisten Machine-Learning-Modelle sind nicht in der Lage, die sogenannten Null-Werte zu verarbeiten, was ein Modelltraining unmöglich macht.
- Ausreißer können sich negativ auf Performance-Modelle auswirken und beispielsweise Overfitting verursachen.
- nicht-numerische Datenformate und
- seltene Merkmalsausprägungen.
! Tipp: Nutzen Sie Visualisierungen, um Zusammenhänge besser und schneller zu erkennen.
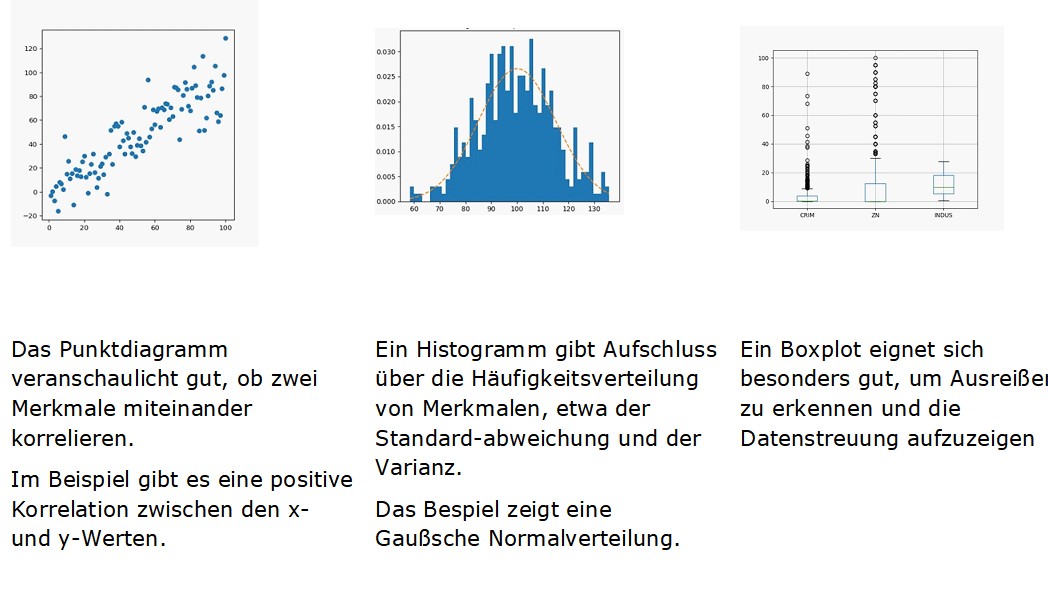
Quelle: it-novum
- Feature Cleansing
Jetzt geht es darum, die erkannten Fehler zu beheben oder weitestgehend zu neutralisieren. Für die Bereinigung fehlender Werte können Sie zwischen zwei Lösungsansätzen wählen: Sie löschen Datensätze, die fehlende Werte enthalten. Oder Sie ersetzen die fehlenden Daten durch gültige Werte (»Imputing«). Die einfachste Variante dabei ist es, wenn Sie diese durch Dummies ersetzen. Sie können Ihr Modell problemlos trainieren, wenn Sie anstelle des fehlenden Werts das Merkmal »Null« einfügen. Sie bilden den Durchschnitt aller Merkmale, die ungleich Null sind, und setzen diesen Wert ein. Bei Zeitreihen setzen Sie an die Stelle des Null-Wertes den letzten oder den ersten nachfolgenden gültigen Wert ein. Sie lassen ein Modell den fehlenden Wert ermitteln.
Den unerwünschten Einfluss von Ausreißern minimieren Sie, indem Sie die Datensätze skalieren. Wenn ein Ziel Ihres Data-Science-Projekts jedoch darin besteht, Anomalien aufzudecken (Anomaly Detection), dann müssen die Ausreisserwerte unverändert im Datenbestand verbleiben.
! Tipp: Stellen Sie Ihre Werte in logarithmischer Form dar, um den verhältnismäßigen Einfluss von Ausreißern zu verringern.
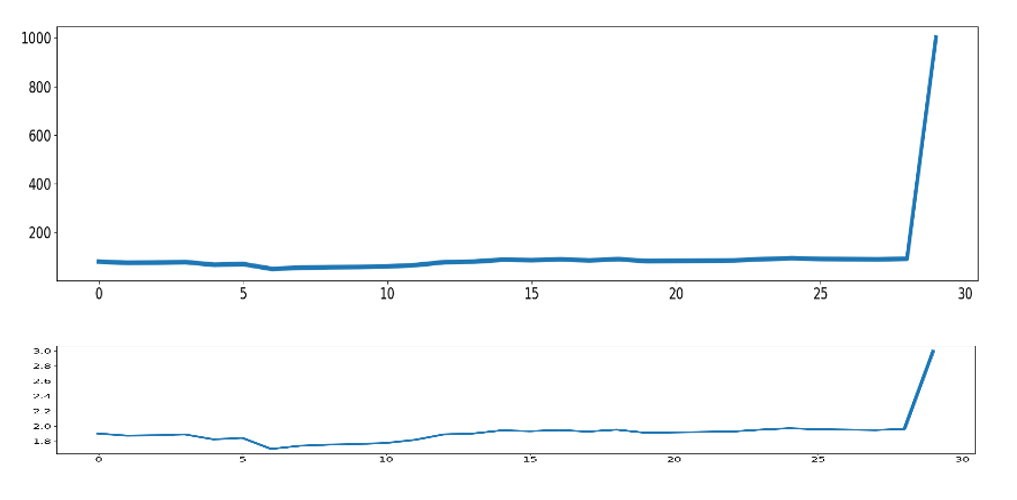
Quelle: it-novum
In der logarithmischen Darstellung (untere Kurve) ist die Abweichung des Ausreißers vom Mittelwert bedeutend kleiner und hat damit ein viel geringeres Gewicht auf die Gesamtheit der Daten.
- Feature Engineering
Bei sehr vielen Einzeldaten eines Merkmals ist es sinnvoll, Werte zusammenzufassen (Diskretisierung). Mit der verringerten Anzahl an Merkmalsausprägungen sinkt der Rechenaufwand und Ihr Modell benötigt weniger Zeit für die Trainingsphase.
! Tipp: Insbesondere bei kontinuierlichen Wertereihen ist es empfehlenswert, Daten zu diskretisieren.
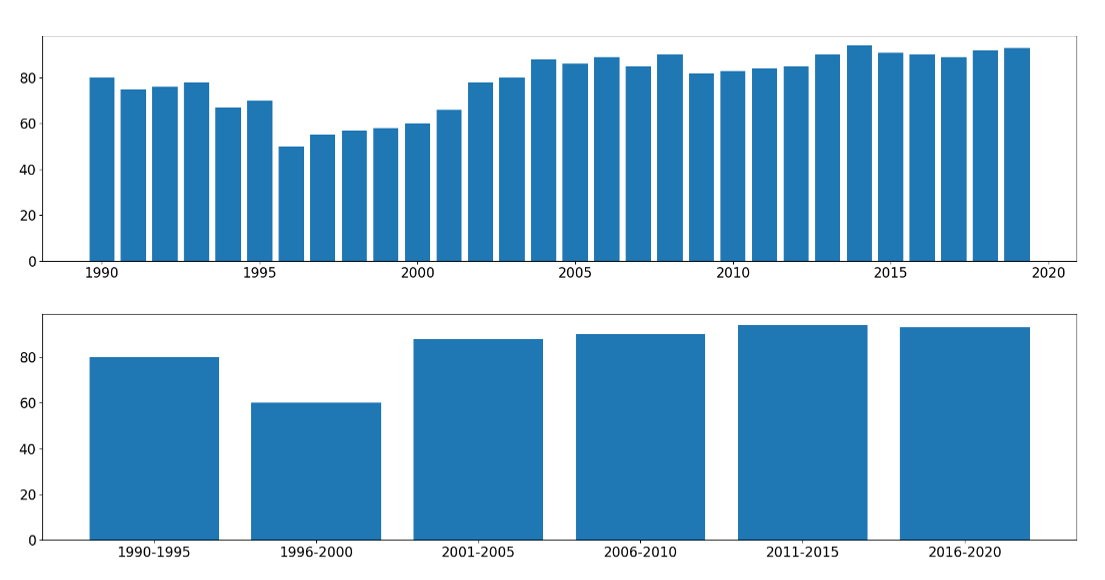
Quelle: it-novum
Ohne relevanten Informationsverlust verkürzen Sie durch Daten-Diskretisierung die Trainingszeiten für Ihr Modell.
Liegen Daten auch in einer anderen Form als Zahlen vor, beispielsweise als Texte oder Bilddaten, müssen Sie diese ggfs. nun in numerische Werte überführt werden. Abhängig ist dies vom gewählten ML-Modell.
! Tipp: Nutzen Sie dafür das One-hot Encoding-Verfahren.
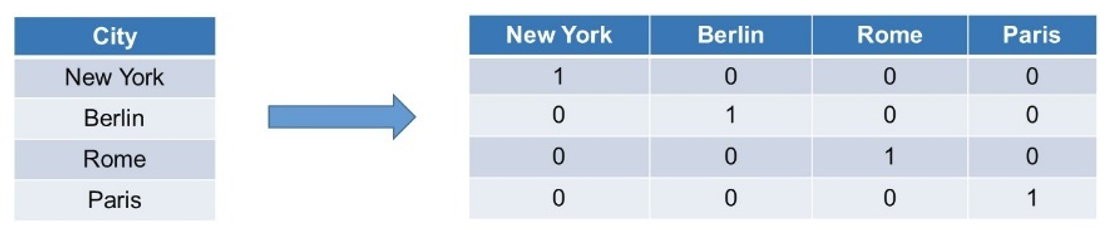
Quelle: it-novum
Für jede Merkmalsausprägung, im Beispiel sind das die verschiedenen Hauptstädte, legen Sie eine eigene Spalte an. Dort, wo die Zeile der ursprünglichen Datenreihe einen Wert in Form des Textes enthält, tragen Sie die Zahl 1 in die entsprechende Zelle ein, alle anderen Zellen enthalten eine 0.
- Feature Selection
In der letzten Phase der Data Preparation bestimmen Sie die Merkmale, mit denen Sie Ihre Predictive-Analytics-Modelle trainieren wollen. Eine Beschränkung ist sinnvoll, da die Modelle umso mehr Trainingszeit benötigen, je mehr Merkmale in die Berechnungen einfließen und es Modelle gibt, die überhaupt nur mit einer begrenzten Datenzahl arbeiten können. Eine Möglichkeit, die Daten sinnvoll auszuwählen, besteht darin sie zu filtern – nach ihrer Relevanz zur Zielvariablen oder nach der Anzahl der fehlenden Werte.
! Tipp: Verzichten Sie auf Daten, die mit dem Feature, das Sie in Ihrem Data-Science-Projekt modellieren wollen, in keinem Zusammenhang stehen.

Quelle: it-novum
Sie können ebenso eine modellbasierte Selektion vornehmen, wenngleich diese Vorgehensweise sehr rechenintensiv ist. Dabei wird das Modell mehrmals trainiert – mit verschiedenen Merkmalkombinationen. Im Anschluss lässt sich daraus ableiten, welche Kombinationen sinnvoll oder weniger sinnvoll sind.
! Tipp: Nutzen Sie Modelle, die auf Grundlage von Entscheidungsbäumen arbeiten, etwa Random Forests. Diese Modelle ermitteln datenbasiert, welche Bedeutung ein Merkmal für die Vorhersage hat, so dass Sie sich für die weitere Modellierung auf diese Features konzentrieren können
Nun ist die Datenvorbereitung durchgeführt und es schließt sich die Modellierung an.
Der erste Schritt besteht darin, ein oder mehrere Modelle auszuwählen. Wesentliche Kriterien sind die Art der gewünschten Vorhersagen, Datenbeschaffenheit und -menge. Sobald feststeht, welches Modell am geeignetsten ist, folgt seine Trainingsphase. Ziel ist es, die bestmögliche Vorhersagegenauigkeit zu erreichen.
Michael Deuchert, Data Scientist, it-novum GmbH (www.it-novum.com).
[1] https://it-novum.com/ressourcen-downloads/data-preparation-in-data-science-projekten/?utm_source=manage-it&utm_medium=media
229 Artikel zu „Data Science“
Apache-Spark-Studie zeigt Wachstum bei Anwendern und neuen Workloads wie Data Science und Machine Learning

Zum besseren Verständnis der zunehmenden Bedeutung von Spark bei Big Data hat die Taneja Group ein großes Marktforschungsprojekt durchgeführt und rund 7.000 Teilnehmer befragt. In die weltweit angelegte Analyse wurden Führungskräfte aus Technik und Verwaltung einbezogen, die unmittelbar mit dem Thema Big Data zu tun haben. Die mit überwältigender Resonanz abgeschlossene Studie gibt Aufschluss die…
NEWS | BUSINESS INTELLIGENCE | DIGITALISIERUNG | KOMMENTAR | LÖSUNGEN | SERVICES
Die neue Rolle von BI: Data Science für Jedermann
Daten sind das neue Gold. Nur danach muss gegraben und geschürft werden. Ein schweißtreibender Job, wenn Anwender nicht die richtigen Werkzeuge zur Hand haben. Welche Rolle Bottom-up-Strategien und User Experience bei der Umsetzung erfolgreicher BI-Strategien haben, zeigt Tableau derzeit eindrucksvoll mit einer Reihe an neuen Features und Produkten. Mit der digitalen Transformation nehmen Volumen und…
NEWS | TRENDS 2020 | TRENDS WIRTSCHAFT | BUSINESS INTELLIGENCE | DIGITALISIERUNG | KOMMUNIKATION | LÖSUNGEN | SERVICES
Mehr als 40 Prozent der Data-Science-Tätigkeiten werden bis 2020 automatisiert sein

Laut des IT-Research und Beratungsunternehmens Gartner werden bis zum Jahr 2020 mehr als 40 Prozent der Data-Science-Tätigkeiten automatisiert sein – dies hat sowohl eine Produktivitätssteigerung zur Folge als auch eine intensivere Nutzung von Daten und Analytics durch sogenannte »Citizen Data Scientists«. Laut Gartner können Citizen Data Scientists die Lücke zwischen den Mainstream-Self-Service-Analytics der Businessanwender und…
LÖSUNGEN | AUSGABE 7-8-2016
Wettbewerbsvorteile durch Data-Science

In allen Unternehmen mit mehr oder weniger komplexen Geschäftsprozessen ist die heute anfallende Datenmenge enorm. Es hat sich mittlerweile herumgesprochen, dass eine gezielte Analyse dieser Daten unterschiedliche positive Effekte für ein Unternehmen bringt. Der Bedarf an Data-Science-Know-how ist deshalb groß wie nie, und der Kampf um diese Ressourcen zwischen den Abteilungen ist bereits in vollem Gange.
NEWS | TRENDS WIRTSCHAFT | BUSINESS | BUSINESS INTELLIGENCE | DIGITALE TRANSFORMATION | EFFIZIENZ | TRENDS GESCHÄFTSPROZESSE | STRATEGIEN
Intuitiv versus faktenbasiert: Nachholbedarf bei Data-Science-Nutzung

An der Bedeutung intelligenter Datenanalysen als Innovationsmotor und Treiber der digitalen Transformation herrscht in neun von zehn deutschen Firmen keinerlei Zweifel mehr. Für die meisten von ihnen steht der geschäftliche Nutzen von Data Science inzwischen außer Frage. Gleichwohl vertraut noch immer jedes zweite Unternehmen bei wichtigen Entscheidungen eher der menschlichen Intuition als computergestützten Analysen und…
NEWS | SERVICES | STRATEGIEN | AUSGABE 11-12-2019
Wissen in Datenbanken entdecken – 5 Mythen rund um Data Mining

Data Mining ist kompliziert, ein vorübergehender Trend, benötigt enormes Fachwissen, erfordert riesige Datenbanken und eignet sich zudem nur für bestimmte Branchen. Alles Vorurteile, die leicht zu revidieren sind.
NEWS | TRENDS 2020 | BUSINESS INTELLIGENCE
Die Trends für Business Intelligence & Big Data 2020

Welche Trends für Business Intelligence (BI), Data & Analytics werden das Jahr 2020 prägen? Im Interview gibt BARC-Chef-Analyst Dr. Carsten Bange seine Prognosen ab. Außerdem stellt er exklusiv die Ergebnisse des BARC BI Trend Monitor 2020 vor, der 2.650 Anwender von BI-Technologie zu ihren persönlichen Trendthemen befragt hat. Dr. Carsten Bange, Gründer und Geschäftsführer von…
NEWS | BUSINESS INTELLIGENCE | BUSINESS PROCESS MANAGEMENT | EFFIZIENZ | FAVORITEN DER REDAKTION | ONLINE-ARTIKEL | STRATEGIEN
Big Data: Wo die wilden Daten leben

Data Lakes, Data Marts, Data Vaults und Data Warehouses. Worin unterscheiden sich die verschiedenen Ansätze der Dateninfrastruktur? Big Data oder Data Analytics sind einige der größten Herausforderungen für die IT unserer Zeit. Viele Unternehmen befinden sich inmitten einer Umstellung auf eine datengesteuerte Ausrichtung ihrer Organisation und sind auf der Suche nach der dazu passenden Dateninfrastruktur.…
NEWS | BUSINESS PROCESS MANAGEMENT | EFFIZIENZ | INFRASTRUKTUR | LÖSUNGEN
Klimawandel und Big Data: Ein Speichersystem ohne Grenzen für die Erdbeobachtung
Was hat sich durch den Klimawandel auf der Welt verändert? Was bedeutet das für die Menschen? Welche Maßnahmen sind wichtig, um den Klimawandel zu stoppen – oder um zumindest seine Folgen zu bewältigen? Diese Fragen stehen nicht erst seit Greta Thunberg im Fokus des öffentlichen Interesses und werden auch in Zukunft eine zentrale Rolle spielen.…
NEWS | BUSINESS INTELLIGENCE | BUSINESS PROCESS MANAGEMENT | KÜNSTLICHE INTELLIGENZ | ONLINE-ARTIKEL
Das Potenzial von Machine Learning in einem Data Lake
Egal um welche Branche oder Unternehmensgröße es sich handelt: Daten sind unverzichtbar geworden, wenn es darum geht, fundierte Entscheidungen zu treffen oder Prozesse zu optimieren. Dazu müssen die gewaltigen Datenmengen, die Unternehmen heute ununterbrochen generieren allerdings erst erschlossen und nutzbar gemacht werden. Die Grundlage dafür bildet der Data Lake (Datensee), ein zentrales Repository, in dem…
NEWS | BUSINESS INTELLIGENCE | STRATEGIEN | AUSGABE 3-4-2019
Big Data im Alltag – Wie die Analyse großer Datenmengen unser aller Leben beeinflusst

Internetrecherche, Online-Shopping, Online-Verträge, Navi- und Gesundheits-Apps benötigen immense Mengen an Daten, um valide Ergebnisse zu liefern. Nahezu jeder Bereich des täglichen Lebens kann in Zukunft durch Big Data beeinflusst werden.
NEWS | BUSINESS INTELLIGENCE | ONLINE-ARTIKEL | SERVICES | STRATEGIEN
Fünf Vorurteile über Data Analytics

Die Entwicklungen von Big Data, Machine Learning und künstlicher Intelligenz werden 2019 wieder zu einem spannenden Jahr machen. Dank der Zukunftstechnologien gewinnt vor allem die Datenanalyse an Fahrt und Unternehmen werden noch weniger um die effektive Auswertung ihrer Informationen herumkommen. Manch einer tut sich aber schwer mit dieser neuen, tragenden Säule im Geschäftsalltag. IT-Experten sehen…
NEWS | CLOUD COMPUTING | DIGITALISIERUNG | INFOGRAFIKEN | KÜNSTLICHE INTELLIGENZ | LÖSUNGEN | SERVICES
Big Data killed the Radio Star? Wie künstliche Intelligenz die Musikindustrie beeinflusst

Schon immer war die Musikindustrie eine, die sich konstant weiterentwickelt und an die Gegebenheiten der Welt angepasst hat. Mittlerweile hat mit Streaming, Cloud Computing und Algorithmen eine neue Ära dieser begonnen. Künstliche Intelligenz hat nicht nur die Prozesse in der Branche revolutioniert, sondern hilft uns auch dabei, Musik auf eine neue Art und Weise wahrzunehmen…
NEWS | BUSINESS INTELLIGENCE | TRENDS CLOUD COMPUTING | CLOUD COMPUTING | TRENDS SERVICES | TRENDS 2019 | KÜNSTLICHE INTELLIGENZ | SERVICES
»Data Analytics«-Markt: Machine Learning – Preise sinken, die Produktreife steigt
»Machine Learning as a Service« ist zu einem umkämpften Markt geworden, in dem sich nahezu alle wichtigen IT-Provider positionieren. Sie müssen die Funktionen, zugrundeliegenden Algorithmen und Modelle dabei qualitativ wie quantitativ schnell weiterentwickeln, um Marktanteile und Kunden zu gewinnen. Dies stellt der neue große Anbietervergleich »ISG Provider Lens Germany 2019 – Data Analytics Services &…
NEWS | BUSINESS INTELLIGENCE | CLOUD COMPUTING | DIGITALISIERUNG | ONLINE-ARTIKEL | RECHENZENTRUM | TIPPS
Data- & Analytics-Trends 2018: Flexibel Daten analysieren und integrieren

Business Intelligence, Big Data, IoT und künstliche Intelligenz haben eins gemeinsam: Sie alle drehen sich um Daten und ihre Auswertung. Um bestmöglich von den neuen Technologien zu profitieren, benötigen Unternehmen geeignete Datenplattformen und Analytics-Lösungen. Hier kommen fünf aktuelle Trends, die zeigen, worauf es ankommt. Die Fähigkeit, Daten zu sammeln und auszuwerten, ist heute essenziell für…
NEWS | BUSINESS | DIGITALE TRANSFORMATION | EFFIZIENZ | KOMMENTAR | MARKETING | ONLINE-ARTIKEL
Data Scientists statt Marketingfachleute

Zalando will mehr Data Scientists für datenbasiertes Marketing einsetzen und Werbefachleute entlassen. Die künstliche Intelligenz (KI) soll das Feld übernehmen und das am besten schon morgen. Warum dieser Plan recht riskant sein dürfte, erklärt Philippe Take in diesem Artikel. Einer der größten Online-Modehändler möchte seinen Kleiderschrank ausmisten. Der Stoff der Zukunft sind Daten. Und…
NEWS | BUSINESS | BUSINESS INTELLIGENCE | DIGITALISIERUNG | INFOGRAFIKEN | KOMMUNIKATION | SERVICES
Data Scientist in Programmatic

Die Harvard Business Review kürte den »Data Scientist« kürzlich zum attraktivsten Beruf des 21. Jahrhunderts. Doch was tut ein Experte, der zwischen Big Data, Analytics und Business Intelligence angesiedelt ist, in seinem Arbeitsalltag? Und welche Fähigkeiten sollte er dafür mitbringen? Die Programmatic-Media-Buying-Plattform Tradelab hat für das spannende Berufsfeld eine Infografik erstellt. Diese zeigt auf, was…